1. Adjustable Real-Time Style Transfer (ICLR 2020)
针对什么问题
本文指出基于现有风格迁移算法训练得到的模型,只能生成固定内容结构及风格模式的Stylized Images(风格化图)。此外,选取不同的风格图作为输入,总是得调整损失函数中每一层卷积特征的权重$w$,一旦使用者对生成的结果不满意,就要重新训练该模型。
提出什么方法
本文提出一种可以在训练和测试阶段自动调整关键参数的方法,使得训练得到的风格迁移模型可以通过调整参数,生成风格迥异的Stylized Images。
效果怎么样
本文的方法通过训练一个单一的模型,和多次训练得到的不同风格迁移模型,在生成的Style Images上达到相似的效果。
1.1 Model
本文的模型如下图所示:
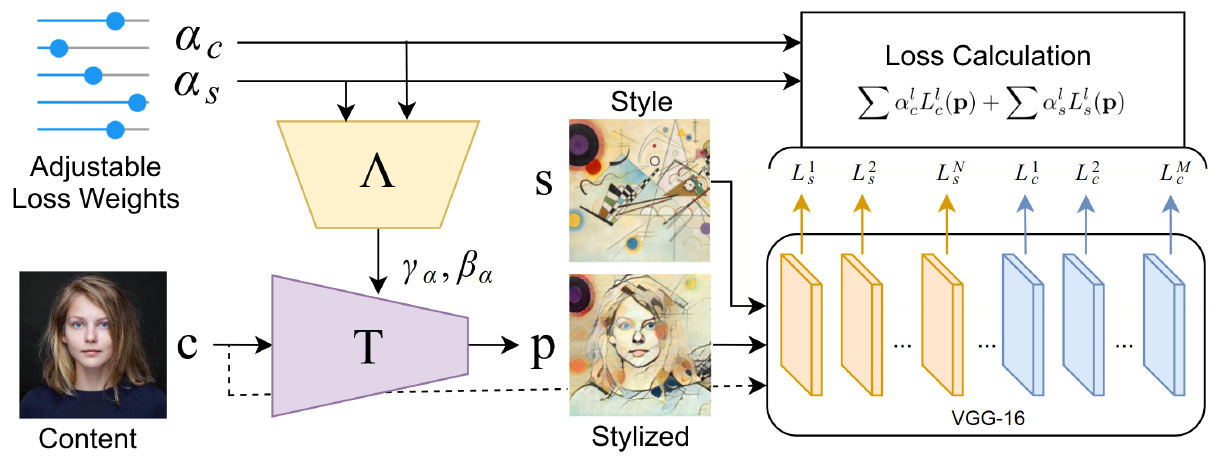
模型的构造很简单,和快速风格迁移的模型类似,最大的区别在于新加入的可调节损失权重$\alpha_c, \alpha_s$,用于替代原始的快速风格迁移模型中计算内容损失$L_c$和风格损失$L_s$的的权重。
此外, 不仅加入到损失函数中,还通过训练前馈神经网络$\Lambda$并以CIN(Conditional Instance Normalization)的方式得到以改变激活层的输出(如下面公式所示)。因此,在测试的时候可以通过调节以调节生成器的输出。
本文的实验提到了训练中$\alpha_c, \alpha_s$的取值。
本文采用预训练的Vgg19提取特征。
本文使用$conv3$提取内容特征,故$\alpha_c = 1$,也就是说$\alpha_c$的取值固定不变。
- 本文使用$conv2, conv3, conv4$提取风格特征,所以这三层中$\alpha_s$的取值随即从$U(0, 1)$中采样。
1.2 Optimization
本文采用的就是常规的风格迁移算法损失:
最大的区别就是,将原始的损失权重$w$替换成了可调节的$\alpha$
1.3 Experiment
本文做的实验主要有以下几方面
- 验证可调节参数的有效性
- 通过可调节参数,生成随机化的Stylized Images
- 和已有的BaseLine作比较
下面挑选几个实验做讲解

- 由于实验中,$\alpha_c$固定为1, $\alpha_s$的三个值可调节,故作者分别固定$\alpha_s$中其他两个值不变,剩余的一个值从0至1调节,得到上图的结果。可以发现,当调节不同层所对应的$\alpha_s$时,生成的Stylized Image风格变化的模式是不同的。这也凸显了作者方法的有效性。

- 在上面的实验中,作者通过常规的方法调节参数训练单一模型作为base,并调节关键参数使得自己的模型权重和单一模型一致。可以看出,作者的方法生成的图像和多个单一训练的模型生成的图像效果较为接近,这也说明了通过本文的方法,训练单一的模型在一定程度上能取代多个模型。

- 在上面的实验中,作者通过改变$\alpha$值和往内容图中填充高斯噪音以获得不同效果的Stylized Images。图中第一行是改变$\alpha$值,图中第二行是往内容图田中噪音,图中第三行是两种方法的结合。可以看到,生成的Stylized Images的确取得了不同的生成效果。
2. Sym-Parameterized Dynamic Inference for Mixed-Domain Image Translation(ICCV 2019)
针对什么问题
本文指出现有的图像翻译方法在没有数据集的情况下,难以学习到领域知识。比如说跨领域知识。如有晴天、阴天、雨天三种数据集,现有的方法只能生成各自领域的知识,却无法学习到混合领域的知识。
提出什么方法
本文提出将多领域的概念扩展到损失领域,并可以动态的生成混合领域的图像。说白了,就是通过在网络中加入参数,动态调节生成图像中3种领域的程度以生成混合领域的图像。
效果怎么样
生成的图像可通过参数Sym-parameters的调节,动态生成混合领域的图像。
2.1 Model
本文的模型如下图所示:
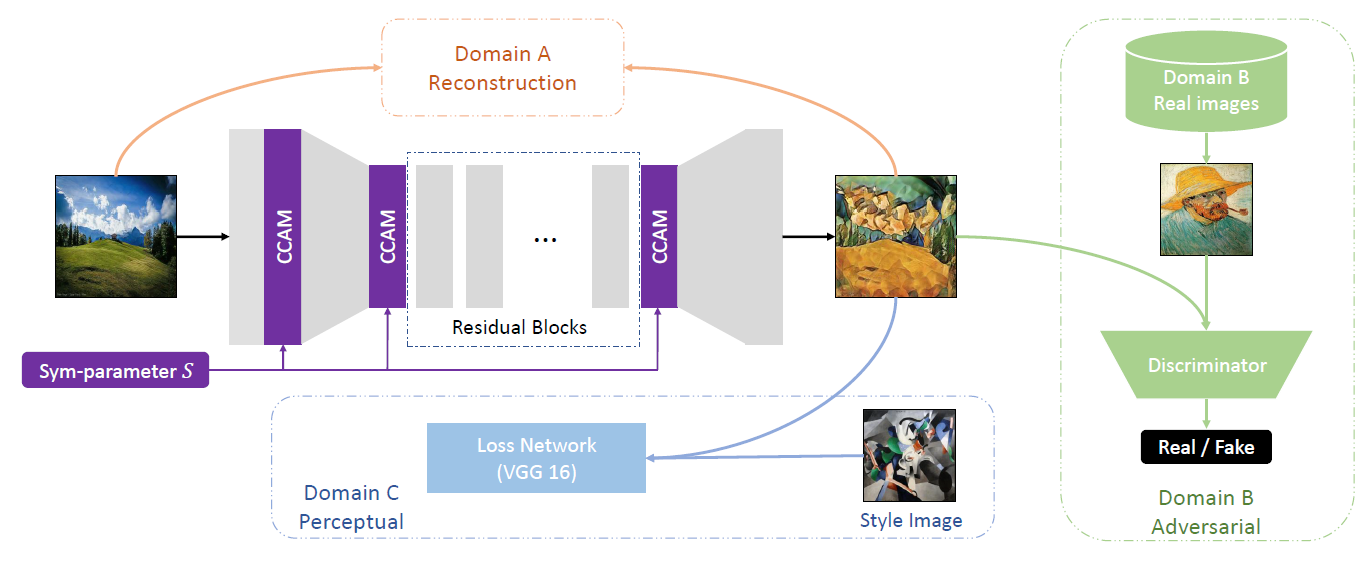
可以看出,该模型的创新指出在于
- 三种领域的数据集混合训练
- 引入Sym-parameters的CCAM模块
我们先来了解以下这三种领域数据集的训练方法
- 单独一个生成网络获得生成图像
- 生成图像分别和三种领域的数据集做以下损失
- Reconstruction Loss
- Perceptual Loss
- Adversarial Loss
- 然后三种损失通过引入Sym-parameters联合起来更新整个模型
然后,我们看看Sym-parameters的含义
- 由于该模型被三种数据集以不同的损失进行训练,故可以通过加入Sym-parameters 同步在模型的网络和模型的损失中控制生成图像占据的领域知识比例。
- ,其维度和损失的个数相同。
- S基于狄利克雷分布采样
- 模型训练完毕后,可以通过调整S来改变生成图像中的混合领域知识的程度
最后,我们讲解一下CCAM模块,如下图所示
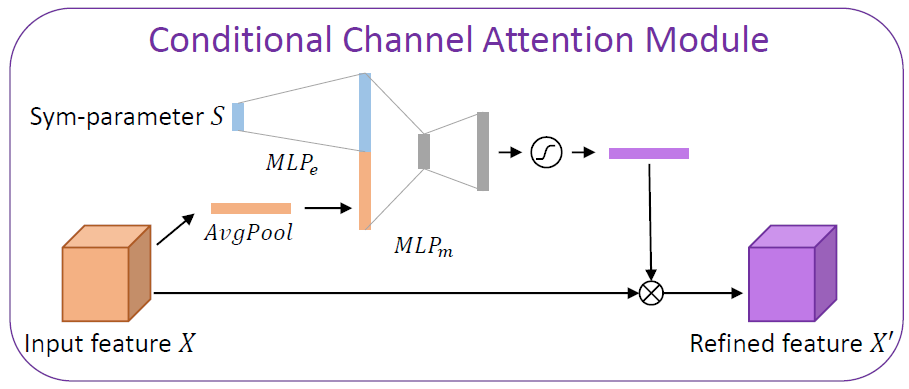
- CCAM模块接收上一层的图像特征和Sym-parameters向量作为输入
- Sym-parameters通过MLP升维再和AvgPool拼接在一起,最后通过全连接层的方式转换为通道注意力权重,和上一层原始特征相乘,得到输出特征
2.2. Optimization
本文的损失很简单,如下:
为了保持一致性,判别器损失也要加上相应的Sym-parameter。
2.3 Experiment
本文做的实验主要体现以下几方面内容
- 证明Sym-parameters的有效性
- 验证是否能够学到混合领域知识
下面挑选几个实验讲解
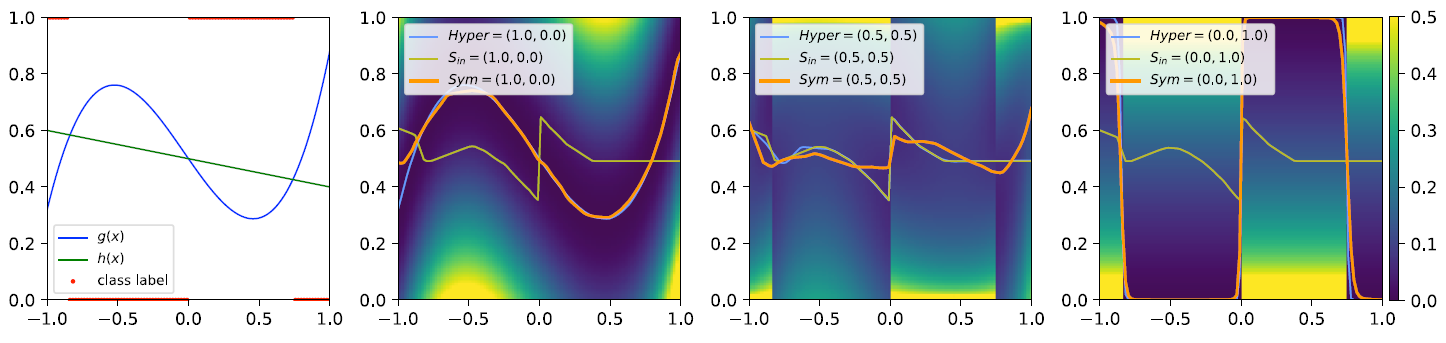
- 在上面的实验中,作者通过1-D的玩具模型同时训练一个MLP网络完成分类和回归的任务。左图是数据集可视化后的结果,右边三张图是在1-D玩具模型中引入Sym-parameters。通过训练单一的基于Sym-parameters的模型,以及基于Hyper-parameters的多个模型,得到以下结论:
- 当Sym-parameters和Hyper-parameters一致时,模型的损失值相同,说明Sym-parameters训练的单一模型的确能够取代多个模型。
- 若固定损失中的Sym-parameters不变,却动态的改变模型中的Sym-parameters,会导致最后的损失值和Hyper-parameters的不一致,说明模型和损失函数中的Sym-parameters需要同步变化。

- 在上面的实验中,作者展示了在Sym-parameter控制下,三个领域互相转化的效果。第一行是,以此类推。最后一行是随机调整Sym-parameters的值,生成图像的情况。值得一提的是,右下角的图像将中间一项设为1.5,使得该领域知识被大大加强。

- 在上图的实验中,作者将本文提出的SGAN和其他多领域转换方法SingleGAN在Sym-parameter于的情况下进行比较。可以看出,SingGAN的输出连原始领域的图像都无法转换,但SGAN因为有重构损失的参与,可以更多的还原原始领域的细节。

- 最后,作者还研究了Sym-parameter的不同注入方法,结果如上图所示。可以看出,CCAM方法生成的图像在风格模式和内容结构上都优于其他方法。
最后,感谢前辈们的付出,Respect!