1. Abstract
- 虽然GAN很成功,但是模式崩塌(Mode Collapse)的问题依然存在,而现在少有论文去理解并量化GAN到底抛弃了哪些模式。
- 故本文在两个级别的基础上可视化了模式崩塌:分布级(Distribution Level)和实例级(Instance Level)。
- 首先,对生成数据集和目标数据集使用语义分割网络,统计两个数据集中被分割出来的物体的分布。分布的不同将会透露出GAN在生成过程中所遗漏的物体。
- 其次,当确定被遗忘的物体类别后,直接可视化GAN遗忘的过程。即比较特定图像的原始版本和通过GAN反演后的版本
- 为了达到可视化的目的,本文放宽了反演问题,解决了GAN某一层反演的问题来替代整个GAN结构的反演。
- 最后,本文使用所提出的框架来分析最近的一些GAN,鉴定他们典型失败的例子。
2. Introduction
- 本文提出一个很有意思的问题:How can we know what a GAN is unable to generate?
- 也即,我们怎样才能知道GAN不能生成什么。
- 虽然GAN很强大,但是模式崩塌(Model Collapse)和模式下降(Model Dropping)的问题依然存在,这表明GAN在生成图像的过程中遗忘了某些目标分布。
- 在下面的描述中,该文章会逐渐将:GAN不能生成什么这个问题转化,然后逐渐提出自己的方法
- 首先,作者表明该文章不是为了判断生成分布和真实分布之间的距离有多远,而是为了理解目标数据集中的真实图像和生成的假图像到底哪里不同。
- 其次,引出问题:Does a GAN deviate from the target distribution by ignoring difficult images altogether? 也即,GAN是否会去忽略比较难生成的图像,从而偏离目标分布。这里我想插一句,学习过GAN的人都应该知道,生成多样性的图像也是GAN的一大挑战。而GAN生成的图像几乎都是数据集中出现概率比较高的图像,所以特殊的复杂的图像的确比较难生成。这个问题问的…感觉挺一般。
- 最后,再将问题转化为:how can we detect and visualize these missing concepts that a GAN does not generate? 也即,我们如何去检测和可视化这些GAN未能生成的概念呢?
- 为此,作者提出在:分布级(Distribution Level)和实例级(Instance Level)上,通过分析场景生成器,来直接理解模式下降。
- 首先,分割生成图像和真实数据集中的图像,比较分割出来的类别的分布。
- 其次,一旦被遗忘的类别找到了,生成这些被遗忘的类别特例的图像,来验证这些类别在生成的过程中是否的确会被GAN所遗忘。
- 最后,本文基于自己的结论做检测,发现
- 被GAN遗忘的类别并不会以扭曲形变的结果展示在生成图上,而是直接被忽略,就好像它们不是场景的一部分。
- GAN的确会忽略比较难以生成的类别,同时输出高平均视觉质量的图像
本文的结论没有想象中惊艳,在不做实验得情况下,通过分析已有GAN的生成结果也可以猜测得出。所以本文的亮点不在于结论,而在于他提出的如何反演GAN的过程,也就是下面要讲的Method。
3. Method
根据上文,本文使用两步来可视化和理解GAN无法生成的语义概念
3.1 在分布级上量化模式崩塌
本文利用图像的场景层次结构来分析GAN的误差,举个例子:使用LSUN bedrooms数据集,GAN若是渲染卧室,也会渲染一些窗帘。若是GAN生成的图像中窗帘的统计数据与真实数据不符合,那么窗帘就是GAN的一个缺陷,即无法生成。
为此,本文使用统一的语义分割网络分割真实图像和生成图像,测量每个对象类的总面积(以像素为单位)和平均值以协方差,并图示了出现次数较高的类别,如下图所示
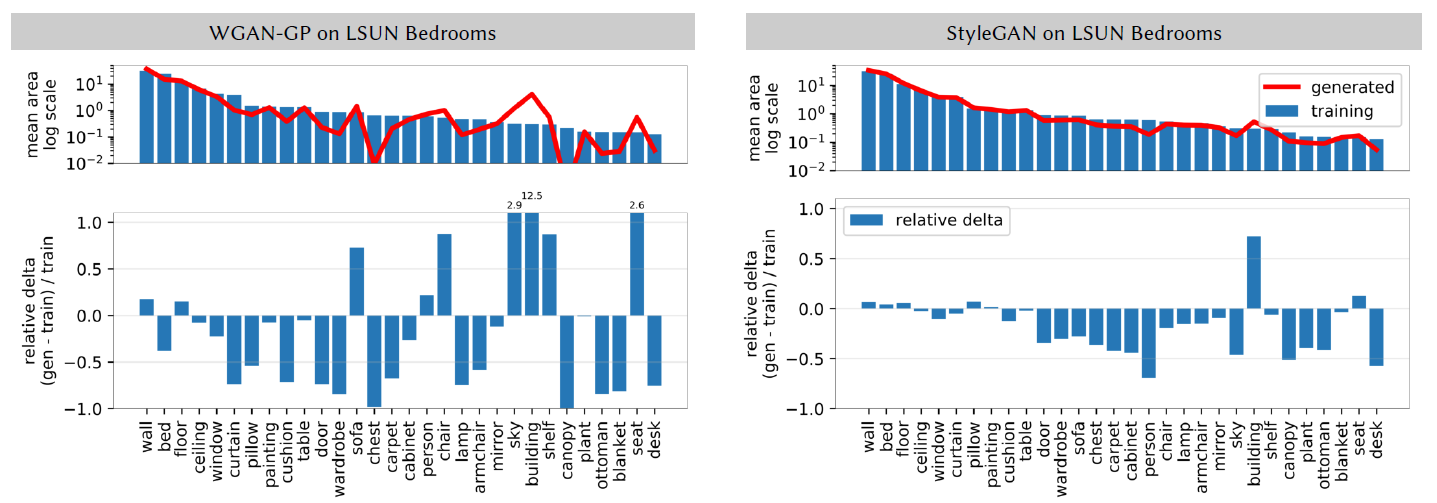
- mean area表明的是类别的面积,红色是生成图像中类别的平均面积,蓝色是真实数据集中各个类别的平均面积。可以看到,WGAN-GP生成的图像中,某几个类别如:chest,canopy等平均面积极其稀少,说明GAN遗忘了它们。StyleGAN的效果比WGAN-GP好很多,但还是出现了遗忘的情况。
- relative delta表明的是相关偏差,即比较生成图像和真实图像中类别的比例,图中的纵坐标也给出了相关的计算公式。可以看到,这里的值和mean area相互照应,部分类别的确生成的过于稀少,被GAN所遗忘
同时,本文仿照FID,提出了FSD(Frechet Segmentation Distance)这一指标
- 其中,$\mu_t$是每个物体类别的平均像素值
- $\sum_t$是这些像素数量的协方差
FSD被用来衡量生成图像和真实图像中分割出来的物体的差异,越低说明差异越小,越好。
3.2 在实例级上量化模式崩塌
虽然上述的FSD能够统计出GAN在生成的过程中,遗漏了哪些特定的类别,却没有指出:GAN在生成图像时,哪里需要物体而它并未去生成。故本文又提出了一种方法来可视化GAN在生成图像时,所遗漏的类别对象。那具体怎么做呢?下面是我在自己阅读论文并理解后的概括。
首先,我们得把问题定义好,所谓的反演就是
- 当我们通过分布级的统计了解到一个训练好的GAN在生成图像时,会忽略哪些类别后
- 我们选定几张存在这些类别的图像,并希望使用GAN生成这些图像时,这些类别是否的确被遗忘了?
- 一旦这些类别在生成的图像中的确不存在,那么就可以得到结论:GAN难以生成什么。
但可能有人会说,让GAN生成图像不是很简单的事情吗,为何需要后面的长篇大论。这也是我一开始困惑的,当我仔细理解后豁然开朗,原因如下
- 让GAN生成图像的确很简单,但是让GAN生成指定内容的图像很困难,因为你不知道指定内容的图像所对应的输入向量是怎么样的。
- 再换个角度解释一下,当一个GAN训练完后,你只能随机采样噪音向量作为输入,生成随机的图像,当然这些图像理论上是符合真实数据集分布的。但是,你无法指挥GAN生成指定内容的图像,你能给的生成条件仅是作为输入的噪音向量。
那么可能就会有同学会想了:我们可以通过反编码的方式得到GAN生成图像的输入向量呀,的确有论文这样去做。当GAN网络层较少的时候是行得通的,但是一旦层数变多,那么效果就很差,文中后面的实验部分也证明了这一观点。
于是,本文定义了一个易于处理的反演问题
将生成器分解成以下形式
其中$g_1, …, g_n$是生成器的前几层,$G_f$是生成器后面所有层的集合
作者指出,任何G能够生成的图像,$G_f$也能够生成,并做了如下定义
也就是说,G能生成的图像是$G_f$生成图像的子集。若是$G_f$难以生成的图像,G同样也生成不了。(为什么?可能是因为$G_f$包含了更多的变化,输入向量的维度远超$z$)
所以问题就变成反演$G_f$,而不是$G$
即最终不是寻找输入向量$z$,而是一个中间表示$r$来作为$G_f$的输入,得到指定内容图像的重构
围绕着上面的定义,作者提出了自己的方法,一共分为三步,如下图所示
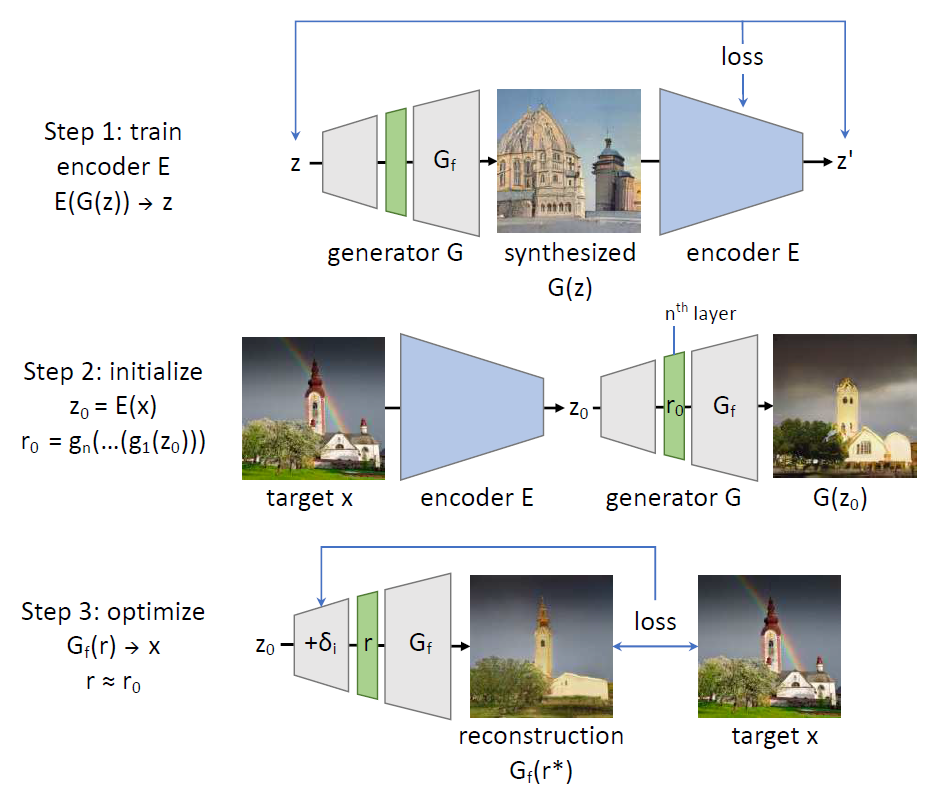
第一步,训练一个编码器E,使得$E(G(z)) \rightarrow z$。那么同学们可能就有疑惑了,不是说直接获得$z$很难吗,那为什么还要得到$z$,岂不画蛇添足。文中是这样解释的,虽然作者的目的是找到一个中间表示$r$来作为$G_f$的输入,但是一个较好的初始$z$将会对寻找$r$有很大的帮助,即得到一个更有和$z$相关的$r$。这一块的关键是如何训练编码器
编码器的训练不是采用端到端的反向传播方式,而是$layer-wise$的方法。专门有相关的论文研究该方法,简单来说就是独立每一层网络的训练,而不是一起训练。
为此,作者对应着$g_i \in \left\{ g_1, g_2, …, g_n, G_f \right\}$将编码器$E$分解为$\left\{ e_1, e_2, … \right\}$,并定义了如下表示
即$e_i$能够还原$g_i$生成的特征,为了使得$e_i$较好的保留$g_i$的输出特征,又定义
训练$e_i$的损失函数如下所示,能够保证双向输出的特征被很好的保留
其中$||.||1$是$L_1$损失,$\lambda_R = 0.01$来强调$r{i - 1}$的重构能力。
那么,编码器$E$就可以表示为
第二步,在得到$z_0$之后,就可以得到初始化的$r_0 = g_n(…(g_1(z_0)))$。
第三步,不断的更新$r$找到最适合的那个$r^*$,最后输入到GAN的$G_f$部分中来恢复对指定生成图像的还原。
寻找到$r^*$的方式是,对生成器早些层不断地做扰动,学习扰动参数$\delta$,如下所示
其中,$l$是基于$VGG$的Perceptual Loss。
根据文中描述,需要训练的参数就是$\delta$。
4. Experiments
在讲解实验之前,说一下实验得配置
- 作者在三个GAN模型上验证了自己的方法,分别是:WGAN-GP,Progressive GAN以及StyleGAN。
- 数据集是:LSUN bedroom images
- 使用:Unified Perceptual Parsing network 来分割图像
4.1 生成图的分割统计
这个在前文的方法中讲过了,作者在实验中直接使用上文提出的$FSD$来衡量真实数据集和生成数据集类别统计的差异,如下表所示:

4.2 敏感度测试
这个敏感度测试,应该是为了验证自己的统计分布的方法并只针对整个数据集有意义,随机采样数据并统计信息也会得到类似的结果。表明了自己方法的泛化性。
4.3 确认抛弃的模式
根据分布级统计到的数据,GAN总是选择性跳过比较困难的子任务,如在生成分布中,人出现的概率很低。通过反演的方法得到的包含被遗漏对象的图像的重构图,也都表明了模型难以生成这些对象。也就是说,GAN并不是以低质量的结果展示这些类别,而是完全遗忘了这些类别,所以这些类别在生成的图像中完全不存在。
4.4 比较Layer-wise和其他方法
这是文中比较大型的实验,主要通过和其他方法对比,以及消融实验,来阐明自己设计的方法是比较合理有效的。整个实验效果图图下,
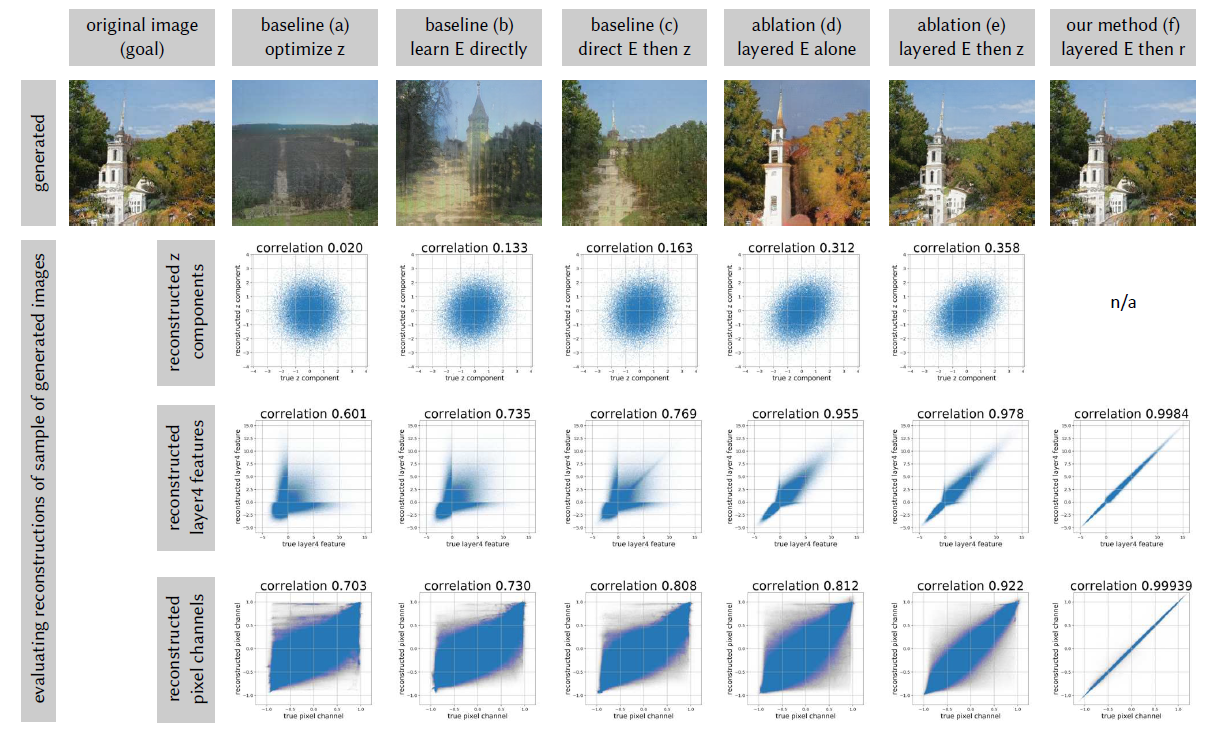
图中的前三列是对比试验,后三列是消融实验。第一行是重构图;由于是对GAN的生成图进行重构,存在$z$的ground-truth,所以第一行是$z$的协相关系数以及图示;第二行是第四层特征的协相关系数;第三行是整个生成图像的协相关系数。下面将对每一列进行详细的解释
- (a)中的方法通过梯度下降优化$z$来最小化重构损失,适用于网络层数较少的生成器,一旦用于层数较多的如15层的Progressive GAN,效果就很差。
- (b)中构造了编码器E来反演生成器但是没有使用layer-wise的优化方法,虽然比起(a)好了很多,但是效果还是很差。
- (c)中先通过方法(b)来初始化$z$,再通过方法(a)对$z$进行梯度更新,效果是好了很多,但是重构的结果仍然不如人意。
- (d)是消融实验,它先通过layer-wise的优化方法得到编码器E,得到对于$z$的初始猜测$z_0 = E(x)$;再直接通过$G(z_0)$的方式得到重构后的图像$x^{‘}$,而未去学习扰动参数$\delta$来得到中间层$r$。实验效果表明,通过layer-wise得到的$z_0$是比较好的,生成的图像比较令人满意,这证明了layer-wise的有效性。
- (e)的实验是在(d)之后,对$z$继续优化来最小化图像的重构损失。虽然定性的结果,重建的图很好,但是$z$的协相关系数很差,这导致我们难以判断重构的错误出在哪里。
- (f)是完整的一套方法,可以接近完美的重建图像,而且各个协相关系数也都很好。所以一旦重建的图像缺斤少两了,并不是重建效果的不好,而是GAN本身问题,是GAN遗漏了那些类别物体。
除了使用生成的图像来做实验,本文还采用了真实图像来测试,以获得定性的结果,如下图所示:

当然,结果也可以证明,本文提出的方法在协相关系数上最高,也就是说重构图最贴近原图。
5. 总结
最后,我总结以下本文的主要内容
- 首先,作者提出问题:GAN存在model dropping的问题,那么GAN到底难以生成哪些东西呢?或者说,GAN到底生成不了什么。
- 为此,作者从分布级和实例级对这个问题进行了回答
- 在分布级上,作者对生成图像和真实图像进行实力分割,统计各类物体的总面积以及相关系数,找到了生成图像中出现次数较少的类别
- 在实例级上,由于找到了出现次数较少的类别,可否再通过GAN重构某些存在这个类别物体的图像,来判断GAN是否遗漏了这些目标
- 故本文提出了基于layer-wise的反演方法,并通过一系列实验证明了其有效性,这也是本文的两点,特别是使用协相关系数。
- 但文中的结论过于简单,那就是:当类别太难了,GAN就不生成了。我觉得是否可以将其归结于多样性的问题,比如数据集中床和窗帘比较多,而人比较少,所以生成的人的概率就小了
最后,感谢本文作者的贡献,respect!