1. Abstract
- 基于深度学习的语义分割有着固有的缺陷:需要大量的数据
- 本文引入self-ensembling,想基于无监督下的领域自适应来解决数据问题,但通过self-ensembling中微调过的人工数据难以缩减语义分割中巨大的领域距离(Domain Gap)
- 为此,本文提出一个由两部分组成的框架
- 首先,基于GAN提出一个数据增强方法,能有效促进领域的对齐(Domain Alignment)
- 其次,基于增强后的数据,将self-ensembling运用到分割网络中以提升模型的能力
2. Introduction
语义分割的任务:给图像中的每个像素点都分类。
大量基于深度学习的算法能够获得较好的效果,但过于依赖数据。为避免人工标注的繁琐和耗时,研究人员利用计算机图形学得到合成数据及所对应的分割标签。而合成数据训练得到的分割模型难以媲美使用真实数据训练得到的,因为存在了称之为领域迁移(Domain Shift)的分布不同(Distribution Difference)。
Unsupervised domain adaptation通过将标记过的数据集中的知识迁移到未标记过的数据集,来解决Domain Shift的问题。
- 最近的方法多集中在对齐源数据和目标数据中抽取到的特征。如基于对抗训练,通过域混肴(Domain Confusion)来最小化领域之间的差异(Domain Discrepancy)。
- 然而,对抗方法也有缺陷,为了对齐两个不同领域的全局分布可能会造成负迁移(Negative Transfer),即将目标特征对齐到了源特征中错误的语义分类。通俗点说,就是将天空的特征或者风格,迁移到了马路上。特别是,数据集中的某个类别比较稀少,更容易产生负迁移。
为解决负迁移,本文引入了self-ensembling。
- self-ensembling由学生网络和教师网络组成
- 学生网络被迫基于老师提供的目标数据,做出协同的预测
- 教师网络的参数是学生网络的均值,所以教师在目标数据上做的预测可以看作是学生的伪标签
- 虽然self-ensembling在图像分类上有很好的效果,若想用于成功对齐领域,它需要大力调节过的人工增强数据。此外,虽然self-ensembling得到的几何变化较大的数据能有效用于分类,它并不适合于语义分割中的Domain Shift。
- self-ensembling由学生网络和教师网络组成
为改进self-ensembling,本文设计了新的数据增强方法
- 基于GAN,生成能够保留语义内容的增强图像。因为未保留语义内容的图像,将会破坏分割的性能,由于增强后的图像和作为源标签的图像在像素上的不匹配。
- 为解决上述问题,该方法于生成器中加入了语义约束(Semantic Constraint),来保留全局和局部的结构。
- 此外,本文提出了目标导向的生成器,能够基于目标领域抽取的风格信息来生成图片。这样,该方法生成的图像又能保留语义信息,又能只迁移目标图像的风格。
大多数Image-to-Image Translation都是依赖于不同形式的Cycle-Consistency
- 有两个限制
- 需要多余的模块,比如两个生成器
- 若是数据不平衡的话,源领域和目标领域的约束过于强烈。也就是说,不管怎么生成,就那几种图像,类似于Model Collapse吧
- 而本文的方法由于它的设计,就不需要考虑Cycle-consistency了
- 有两个限制
整个模型的框架如下图所示
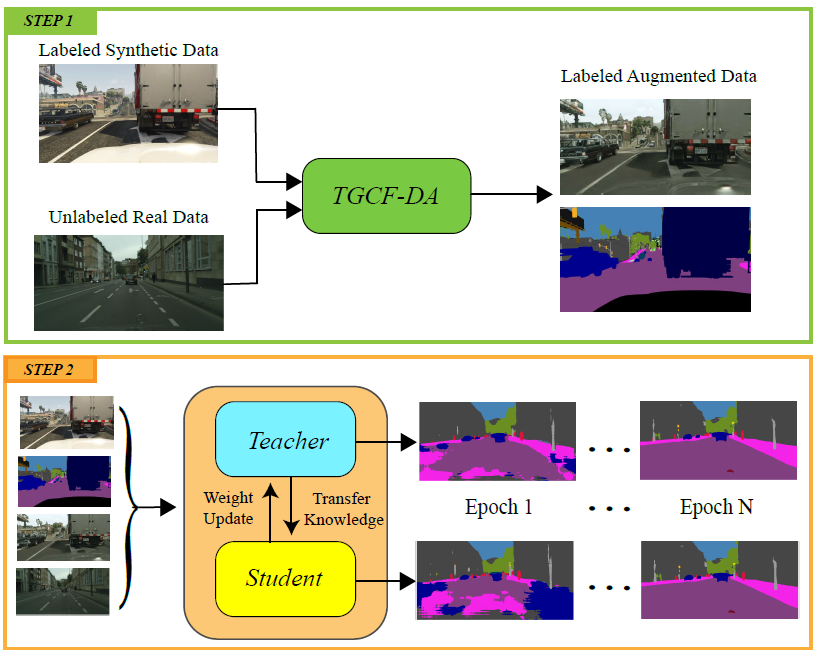
- 步骤一,给定有标签的合成数据及无标签的真实数据,生成带有标签的增强数据(我认为,这里的标签就是源标签)
- 步骤二,作者将关键信息写到了这里,使用两个分割网络作为教师和学生,以使用Self-ensembling算法。这两个网络都使用了合成数据、增强后的数据以及真实数据。在训练过程中,教师网络会将知识迁移到学生网络中。
3. Proposed Method
提升self-ensembling用于语义分割的兼容性的方法是,基于GAN增强后的数据来对齐源领域和目标领域之间的表达,而不是self-ensembling用于分类中的几何转变。为了这个目的,本文设计了以下的模型。
3.1 Target-guided generator
TGCF-DA的模型图如下所示
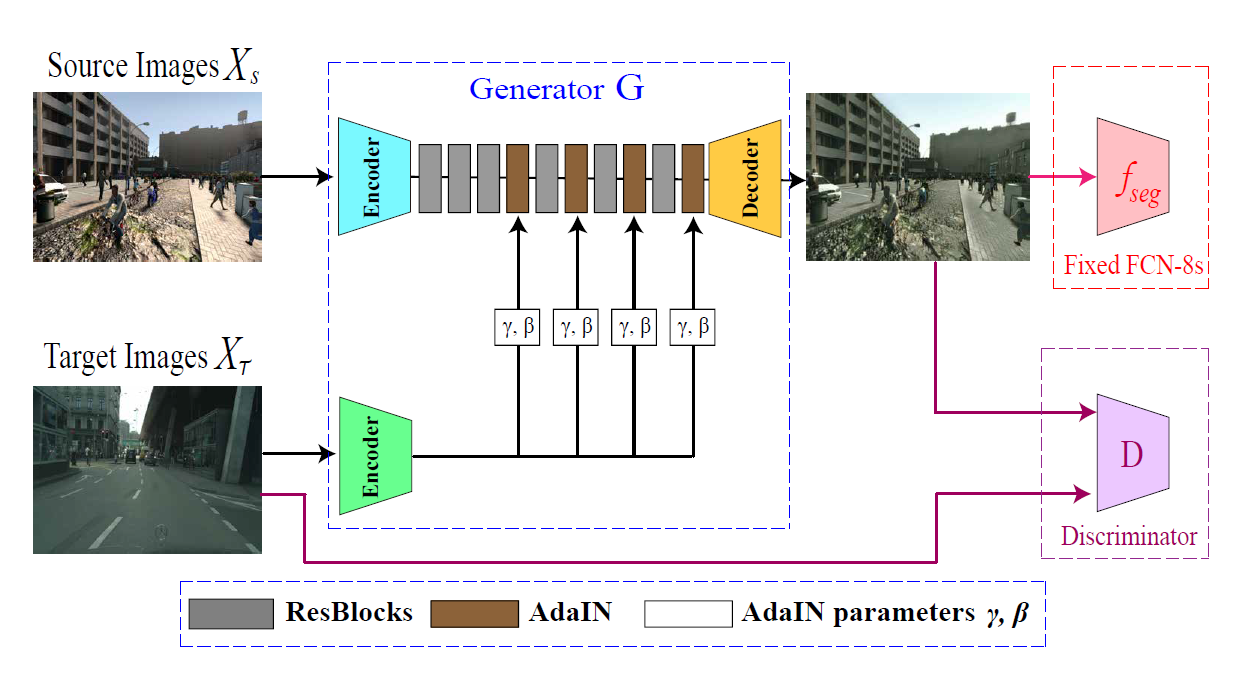
- 基于假设,图像表达可被分为两部分:内容和图像,设计了以上结构
- 使用Souce Encoder来抽取源图像的内容表达
- 再使用Target Encoder来抽取目标图像的风格表达
- 为了结合源图像的内容和目标图像的风格,使用AdaIN算法
- 基于假设,图像表达可被分为两部分:内容和图像,设计了以上结构
根据上面的设计,生成器G得到的图像将会在保留源图像内容的同时,迁移目标图像的风格。也就是改变源图像,如GTA5的虚拟风格,变成现实风格。最后,将生成图像作为fake data,目标领域作为real data,输入判别器。
3.2 Semantic constraint
- 由于没有使用Cycle-consistency,本文使用Semantic Constriant来约束生成图像的语义信息。具体的做法如下
- 设定一个预训练好的分割模型,本文使用的是FCN-8s
- 将生成的图像输入得到分割后的掩码
- 分割后的掩码和源图像的标签做交叉熵
- 这个做法类似于相当于风格迁移中,计算内容损失的做法。
3.3 Target-guided and cycle-free data augmentation
本文对于GAN框架的构建如下
Discriminator的构建是基于Hpix2pix的,详见原文中的参考文献
使用LSGAN的损失作为对抗损失,并基于spectral normalization的方法稳定GAN的训练
对抗损失能够保证G生成的新图像在视觉上和目标图像相似。由于分割模型$f_{seg}$固定了,可以联合训练生成器和判别器来优化总损失
经过上述损失预训练后的生成器,将被用来合成增强数据,为后续的self-ensembling做准备。
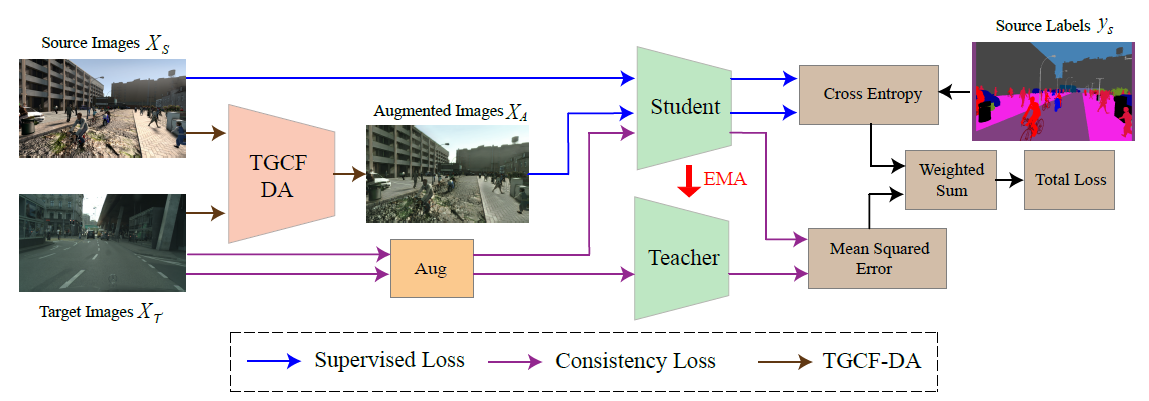
3.4 Self-ensembling
构建了教师网络$f_T$和学生网络$f_S$。步骤t中,教师网络的参数$t_i$由学生网络根据下列公式计算得到
在训练的过程中,每个mini-batch都会包含以下数据
- source samples 源样本
- augmented samples 增强样本
- target samples 目标样本
源样本和增强样本将会被用来计算监督损失$L_{sup}$,即对于语义分割的交叉熵。这个损失函数能使得学生网络,对于源数据和增强数据,都产生语义上更加精准的预测。
一致性损失$L_{con}$是学生网络和教师网络生成的预测图的均方差
这里的$\sigma$是softmax函数,用来计算预测图的概率
总体的损失如下
这里的$\delta_{con}$是一致性损失的权重
3.5 Data augmentation for target samples
看到这一块内容,稍微有些迷糊,特别是作者的第一句话:这里的对于目标样本的数据增强和TGCF-DA并不相关,差点就被带偏了,不知道理解到什么地方了。不过仔细看了一下后面的内容,得到如下理解
- 这里对target samples增强是为了在self-ensembling中计算consistency loss。对于目标样本的随机数据增强,是为了强迫学生网络针对相同的目标样本得到不同的预测,以更好的训练学生和教师网络。
- 根据前文,常规self-ensembling中的几何变换对于像素级别的预测任务并无帮助。因此,本文在目标样本中注入高斯噪声,并分别喂给学生和教师网络。此外,对于网络参数还是用了Dropout。
- 因此,学生网络在目标样本有扰动的情况下,还必须得产生和教师网络一致的预测,这也变相了提升了模型的性能。
4. Experiments
在做实验之前,作者略微详细的介绍了用到的数据集如:GTA5,Cityscapes等。对于实验的配置,作者说的很详细,建议详细阅读。比如TGCF-DA的具体构造,生成器和判别器都是挑了比较好的结构,一起一些超参数的设置。此外,还讲了self-ensembling中,对于分割网络的选择,选择哪一层计算损失等。
4.1 Experimental results
作者将自己的方法与CycleGAN,MCD,DCAN等一堆方法进行比较。该实验首先在GTA5或者SYNTHIA数据集上,训练分割网络,并在Cityscapes的验证集上验证。实验得结果如下表所示
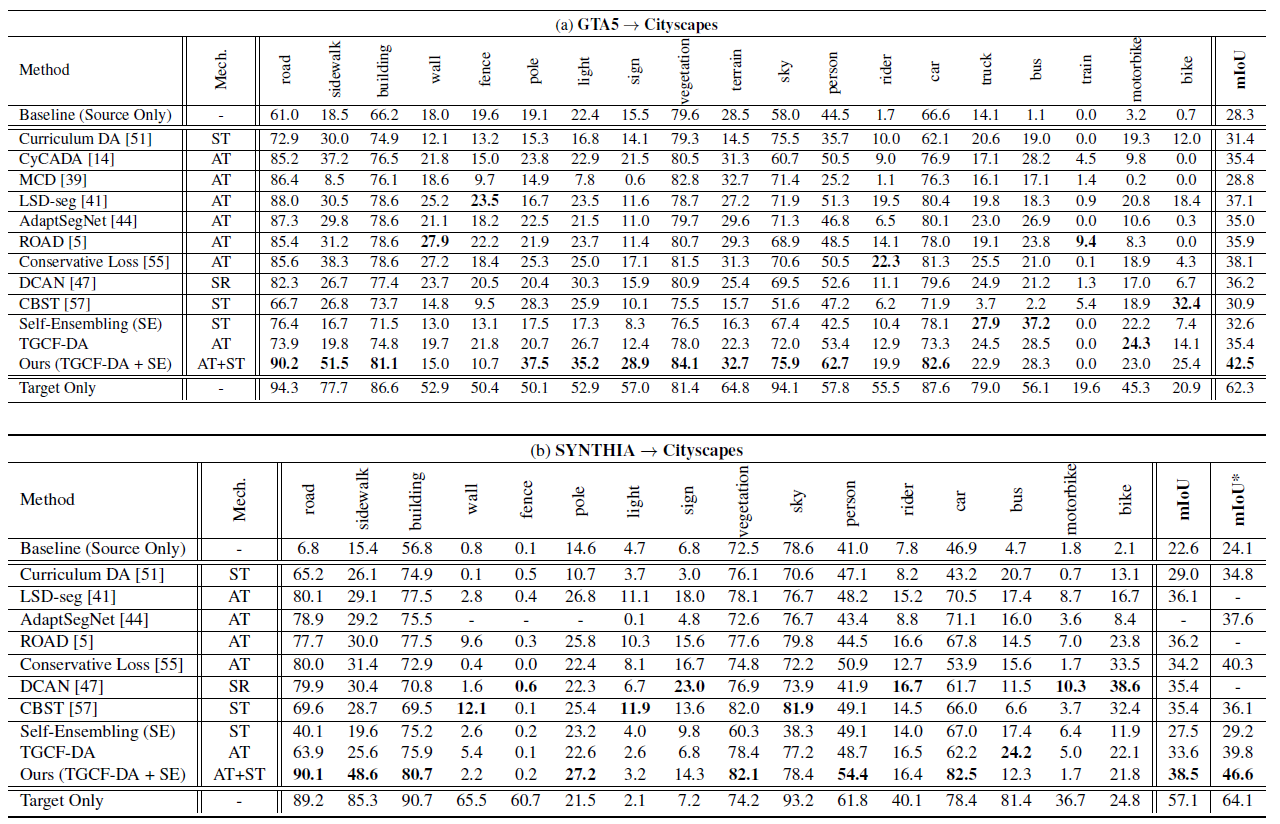
- 表中的Self-Ensembling,代表着由源数据和目标数据(未加入增强数据)训练得到的分割网络的性能
- 表中的TGCF-DA表明由源数据、目标数据、TGCF-DA生成的增强数据,共同训练的分割网络
- 表中的Ours(TGCF-DA + SE)表明结合了TGCF-DA和Self-Enembling方法,得到的分割网络
- 表中的mIoU*代表的是,13个常见类别的mIoU,因为数据集中有些类别出现次数不多。但具体是哪13个类并没有讲,可能会在作者提供的附件里
- 表中的Source Only声明了只在源数据集上训练的分割模型的效果
- 表中的Target Only声明了在监督设定下训练的分割模型的效果
作为刚接触Domain Adaption的小白,对于这个实验一直耿耿于怀。首先是对于表中的Baseline(Source Only)的不理解,其次是对Target Only的不了解。经反复思考后,理解如下
Baseline(Source Only)既然都说了是Source Only,而且文中又把增强后的数据叫做Augmented Data。对应上面的表格,Baseline应该指的就是GTA5和SYNTHIA中的原始训练集,训练得到的分割模型,那效果肯定差。
接下来一系列的方法,CycleGAN,MCD,DCAN等,应该都是使用进行Domain Shift后的数据配合原始的mask标签,来训练分割网络,那为什么效果会差呢?根据文中的描述,原因有二
- 首先是,经过Domain Shift图像的内容结构可能被破坏了,导致原始的mask标签不匹配,从而产生语义上的损失。如,车子经过domain shift之后形状变了,但对应的mask掩码标签却没变,那效果肯定差。
- 其次是,负迁移造成的影响,有些类别过于稀疏,在Domain Shift的时候导致转换有误,如,前面的例子,将马路的知识迁移到了天空上。
然后就是纯Self-Ensembling方法了,效果有一定提升,但是没本文方法提升的多。但作者在前文就指出原始的Self-Ensembling适用于分类网络,但却不太适用于分割网络。我理解是:由于Self-Ensembling是通过形变原始数据得到增强数据,来提升分类模型的性能;而在分割网络中,形变原始数据会导致其和mask标签不匹配,破坏了内容结构,所以效果变差。
最后就是文中提到的两个方法
先是只使用了TGCF-DA,效果并没有好到哪里去,甚至比CycleGAN,MCD,DCAN等方法都要低几个点。这说明,抛弃Cycle Consistency,理想化的将图像分为content和style,并通过AdaIN方法进行结合等一系列操作,并没有达到作者预期的效果。我觉得作者可能一开始只提出了这个方法,做了实验之后发现效果居然没有好太多,再考虑将Self-ensembling的方法加入来提升网络的性能。不过,这个方法还是很有创意,巧妙地将任意风格迁移和GAN结合在了一起,值得我思考。
然后就是TGCF-DA + Self-ensembling,效果简直超神,顺利毕业。原理就是,通过TGCF-DA预训练模型生成增强数据,然后配合学生、老师网络进行训练,最后得到一个更好的分割模型。如下图
4.2 Ablation studies
首先,做了Self-Ensembling的消融实验,如下图
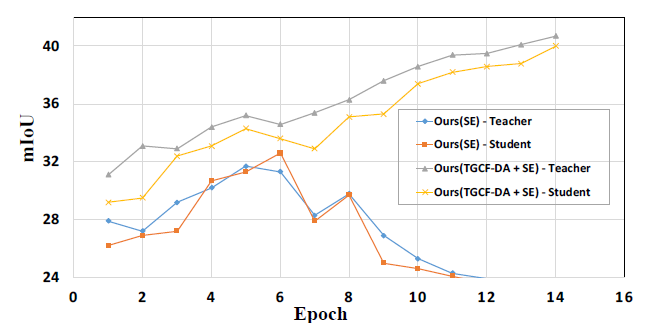
- 在上一实验的表格中,就发现纯Self-Ensembling效果很差
- 这就说明了,主要的功劳并不在Self-Ensembling的应用上,而是TGCF-DA + Self-Ensembling上
其次,做了TGCF-DA的消融实验
- 在上一实验表格中,发现TGCF-DA能有效提升分割模型的效果。
- 其次,通过图示风格模型的mIOU,发现纯Self-Ensembling在第8个epoch就达到了极大值,继续训练效果变差,而TGCF-DA + Self-Ensembling效果持续上升,说明二者结合才是王道。也从侧面说明了TGCF-DA的重要性
在消融实验中,作者想表明TGCF-DA + Self-Ensembling结合的重要性,并将主要功劳放在TGCF-DA上。但正如我前文所说,TGCF-DA的效果和其他方法相差不多,那是否将其他方法和Self-Ensembling结合,也会得到更好的效果呢?不过,这也是我鸡蛋里挑骨头了,本文主要的贡献已经很多了,就比如TGCF-DA + Self-Ensembling结合训分割模型,提升性能,也是本文的卖点。
5. Analysis
在这块内容,作者可视化了几个模块的结果,并进行进一步的分析。
5.1 Visualizaton
首先是对于Self-Ensembling中间结果的可视化,如下图
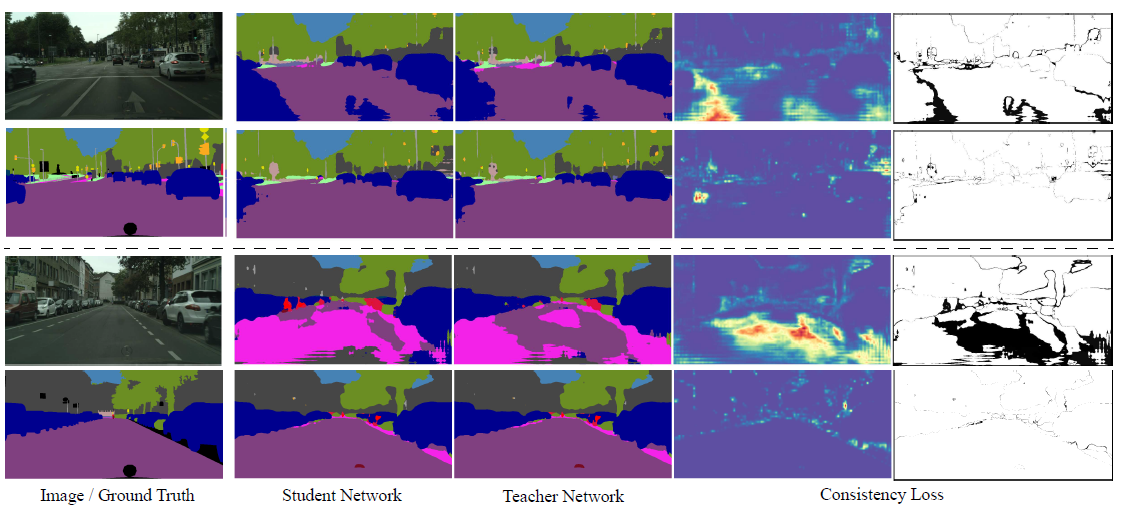
- 图中表明,教师网络能够很好的指导学生网络进行训练。
- 此外,根据热力图可以发现,consistency loss在训练中会逐渐关注到物体的轮廓,从而微调轮廓提升预测的效果。
其次是,可视化自己的增强数据

- 根据作者的描述,大多数方法都扰乱了物体的轮廓
- 甚至,有的方法发生了“负迁移”,就是将天空迁移到了马路上,但作者在这里没提“负迁移”,提了一个叫“spills over”的概念,我思索一下就是“负迁移”。
- 从而,得出自己的方法计算得快,在视觉程度上效果还好。
5.2 Analysis of self-ensembling with per-class IoUs
为了更好的理解self-ensembling,作者比较了在使用self-ensembling下,不同类别精度的提升情况,如下图
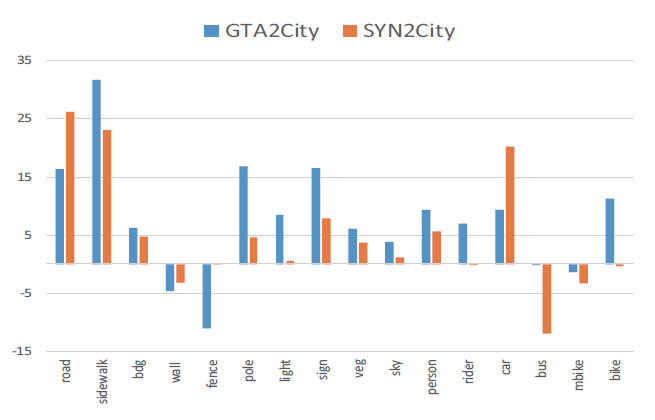
可以看到,每个类别提升的程度不同。作者人为原因是各个类别数据的不平衡。数据越多的类,提升的效果也越明显。在Self-ensembling中,这个效果会越明显。因为学生网络持续学习到教师网络的预测,那么将会不断的在稀少类别上做出错误的预测。这也印证了作者说的:教师网络的预测是学生网络的伪标签。
- 这一块实验个人感觉精华就是:类别越多,提升性能越大
6. Conclusion
- 作者在文章的结尾,还解释了各种超参数的设计和原因,若是对文章感兴趣的朋友可以自行阅读。
- 那么,我在看完这篇文章后,总结如下
- Domain Adaption可以通过迁移真实数据的知识到虚拟数据中,获得增强后的数据,以缓解基于深度学习的语义分割任务中,对于大量标注数据的需求。
- 但是,现有的Domain Adaption方法有以下问题
- 生成的增强图像内容信息损失,如结构紊乱,和源数据的标签不匹配了
- 生成的增强图像发生了“负迁移”,导致知识迁移的位置不正确,如“天空”迁移到“马路”上
- 现有的Domain Shift方法大多基于Cycle-consistency,参数多耗时耗力
- 故本文提出了基于GAN的数据增强方法TGCF-DA
- 两个Encoder,一个抽取源数据的内容,另一个抽取目标数据的风格
- 抽取到的内容和风格通过AdaIN结合在一起构成Generator,生成fake图像
- fake图像,和目标数据集中的图像作为Discriminator的输入,更新Generator
- 但仅用TGCF-DA生成的增强数据训练分割网络和其他的方法效果差不多,故本文又引入了Self-ensembling来训练分割网络。稍微不同的是,原始的Self-ensembling改变图像的形状,但本文是给图像注入高斯噪音。因为改变几何形状会破坏图像和mask标签的匹配性
- 最后,TGCF-DA + Self-ensembling的结合,在实验上取得了令人瞩目的效果
- 我认为本文的亮点如下
- TGCF-DA网络的构造,结合了GAN+任意风格迁移,很新颖
- TGCF-DA + Self-ensembling,说白了就是将Domain Shit方法和Self-ensembling方法结合在一起。
- 我认为本文未解释清楚的就是,没有做实验证明, 其他的Domain Shift方法和Self-ensembling结合在一起,是否也会得到很好的效果
最后,感谢本文作者的贡献,respect!