1. 题目分析
给定一个二维空间数据集T={正实例:(5, 4), (9, 6), (4, 7);负实例:(2, 3), (8, 1), (7, 2)},试基于欧氏距离,找到数据点S(5, 3)的最近邻(k=1),并对S点进行分类预测
- 输入:训练集数据$T = \left\{(5, 4, 1), (9, 6, 1), (4, 7, 1), (2, 3, 2), (8, 1, 2), (7, 2, 2)\right\}$;测试集$S = \left\{(5, 3, _)\right\}$;
- 输出:测试集中样本所属类别y;
- 根据欧氏距离,在训练集T中找出与测试集中S最邻近的k个点
- 统计这k个点中,类别个数最多的点,作为测试样本的类别
k近邻法没有显式的学习过程
2. 算法分析
K近邻完整算法请走传送门,下面将拆解分析
2.1 初始化
# 定义训练集和测试数据
training_set = np.array([[5, 4, 1],
[9, 6, 1],
[4, 7, 1],
[2, 3, 2],
[8, 1, 2],
[7, 2, 2]])
rows = training_set.shape[0]
cols = training_set.shape[1]
S = np.array([[5, 3]])
- 将训练数据存储为2行3列的array,最后一列是每条数据所属类别
- 我们以1作为正例,以2作为负例
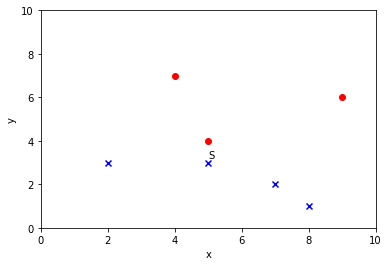
2.2 图示样本
# 方法:画散点图
def plot(sample):
plt.xlabel('x')
plt.ylabel('y')
plt.axis([0, 10, 0, 10])
x = sample[0]
y = sample[1]
cat = sample[2]
if cat == 1:
plt.scatter(x, y, c='r', marker='o')
else:
plt.scatter(x, y, c='b', marker='x')
- 首先,定义好坐标轴刻度,都控制在(0, 10)之间
- 其次,画点
- 若为正例,画红色圈
- 若为负例,画蓝色叉
2.3 欧氏距离
# 方法:计算样本之间的欧式距离
def compute_distance(x_train, x_test):
distance = np.sqrt(np.square((x_train[0] - x_test[0])) +
np.square((x_train[1] - x_test[1])))
return np.array([distance, x_train[2]])
- 即计算训练集中样本和测试集样本的距离
- 需要保留训练集样本所属的类别,便于后面比较距离时调用,故返回的是一个array([两点之间距离,训练样本所属类别])
2.4 遍历样本
# 遍历训练集并计算距离
distance_array = np.zeros([1, 2])
for row in range(rows):
x_train = training_set[row, :]
x_test = S[0]
distance = compute_distance(x_train, x_test)
distance_array = np.row_stack((distance_array, distance))
plot(x_train)
- 首先,定义一个distance_array,用于保存测试样本与训练集中所有样本的距离
- 遍历训练集中的所有样本
- 计算两点之间的欧式距离
- 动态扩展distance_array的大小
- np.row_stack()可在distance_array中加入子项
- 即插入行数据,每行数据为compute_distance()返回的结果
- 同时,将此刻用到的训练集样本在坐标系中画出
2.5 判断类别
# 选取k值,并得到类别
k = 5
distance_array = distance_array[np.argsort(distance_array[:, 0])]
cat_array = distance_array[1: (k+1), 1].astype(np.int32)
max_cat = np.argmax(np.bincount(cat_array))
test_value = np.column_stack((S,
np.array([max_cat],
dtype=np.int32)))[0]
print("The test data belongs to ", max_cat)
- 首先,选取K值,这里我们设置为5,即比较所有数据与测试样本的距离
- 其次,我们调用np.argsort()将测试样本与训练集中样本的根据距离从小到大进行排序,得到排序后的distance_array并返回
- 接着,由于我们初始化distance_array时,默认存入[0, 0],经排序后放在第一行;故删除第一行,取剩下所有行;且只保留类别信息存入cat_array
- 最后,我们调用np.bincount()对cat_array中出现的类别进行统计,并调用np.argmax()取出出现次数最大值,作为测试样本的类别;并将类别加入到测试样本中,便于图示
2.6 图示样本集
# 图示所有点的位置
plot(test_value)
plt.text(test_value[0], test_value[1]+0.2, 'S')
plt.show()
先画出测试样本在图中的位置
并根据y坐标,标记其符号S
整体展示所有样本
3. Sklearn实现
from sklearn.neighbors import KNeighborsClassifier
# 1. 定义K值
k = 5
# 2. 根据参数要求得到训练集和测试集
x_train = training_set[:, :2]
y_train = training_set[:, 2]
x_test = S
# 3. 进行KNN分类
clf = KNeighborsClassifier(n_neighbors=k, n_jobs=1)
clf.fit(x_train, y_train)
y_predict = clf.predict(x_test)
print("The test data belongs to ", y_predict[0])