1. 几个问题
- Anchor和全卷积输出值之间的关系
- “回归系数”是什么,有什么用?
- 在选择RPN Boxes时,既要考虑RPN Boxes与Ground Truth的IOU来筛选,又要考虑每个RPN boxes为物体前景的概率。那么在筛选RPN Boxes的时候,哪个先考虑,哪个后考虑,还是说同时考虑?如果说是同时考虑,又怎么考虑?
2. Anchor Generation Layer
- Anchor主要为了在输入的图像上产生多个可能存在物体的bounding box,所以Anchor肯定是要分布在整个图像上,才能包括所有的物体。那么,在Faster-RCNN中Anchor是如何产生的呢?Anchor的产生下图所示:
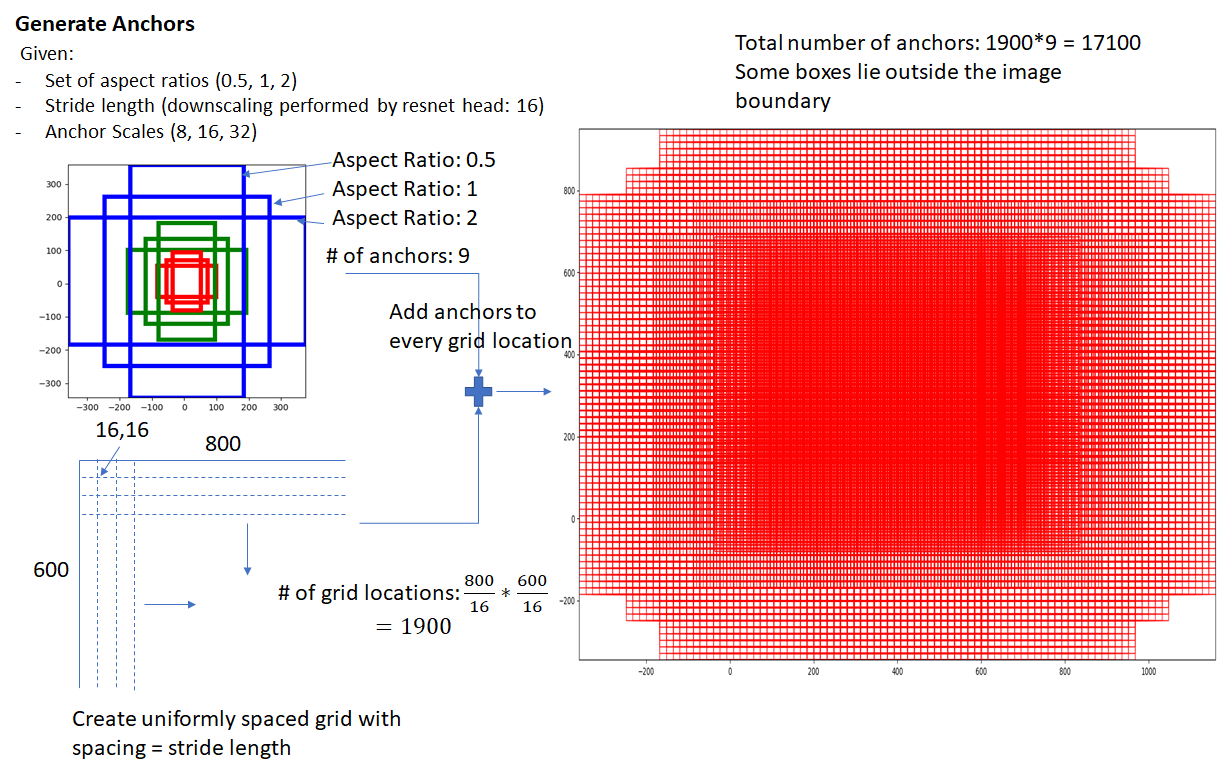
- 初学者很容易犯的错误就是:Anchor其实是神经网络产生的,最后要通过训练才能得到Anchor及图中那么多bounding box。其实不然,Anchor就是通过机械化的操作产生覆盖整张图的bounding box,数量多且杂。和Anchor有关的神经网络做的并不是产生bounding box,而是产生相对应的bounding box的回归系数,回归系数正好也是4个值。我们先来理解什么是所谓的“机械化”,再来理解“回归系数”。
- 对“机械化”的理解可以从上图解释。Faster-RCNN设置了aspect ratio(0.5, 1, 2),以及Anchor Scales(8, 16, 32)。大部分博客说到这里就结束了,他们会说3x3=9,最后一共产生9个anchors。那么到底是怎么计算的呢?详细可以看我通过源码阅读得到的计算过程,传送门在这里。如下面公式所示:
- 综上,我们知道了
- Anchors不是神经网络产生的,而是人为设计的,通过指定aspect ratio和anchor scales两个参数来生成。
- Anchors的原始比例是定义在特征图上的,若是返回到原图的话,需要乘以相应的倍数
- 仍有一个问题没有解决,Anchors和回归系数之间的关系?我们继续往下看
3. Region Proposal Layer
在Faster-RCNN之前,R-CNN通过selective search method来生成region proposal,但是速度慢、效率低,故Faster-RCNN通过Anchors来生成候选框,如上述。然而,Anchors生成的框就可以直接用了吗?我们看到那么多密密麻麻的生成框,而且还是最最简单的通过比例放缩得到的,肯定是需要进行筛选和回归的。那么,Region Proposal Layer就是完成了筛选和回归的工作,具体如下:
- 从一系列生成的anchors中,确定哪些是前景,哪些是背景
- 通过一系列的“regression coefficients”即回归系数修正anchors的位置、宽度及高度,来提升anchors的质量。
Region Proposal Layer一共包含三层:Proposal Layer, Anchor Target Layer以及Proposal Target Layer。整体结构如下图所示:
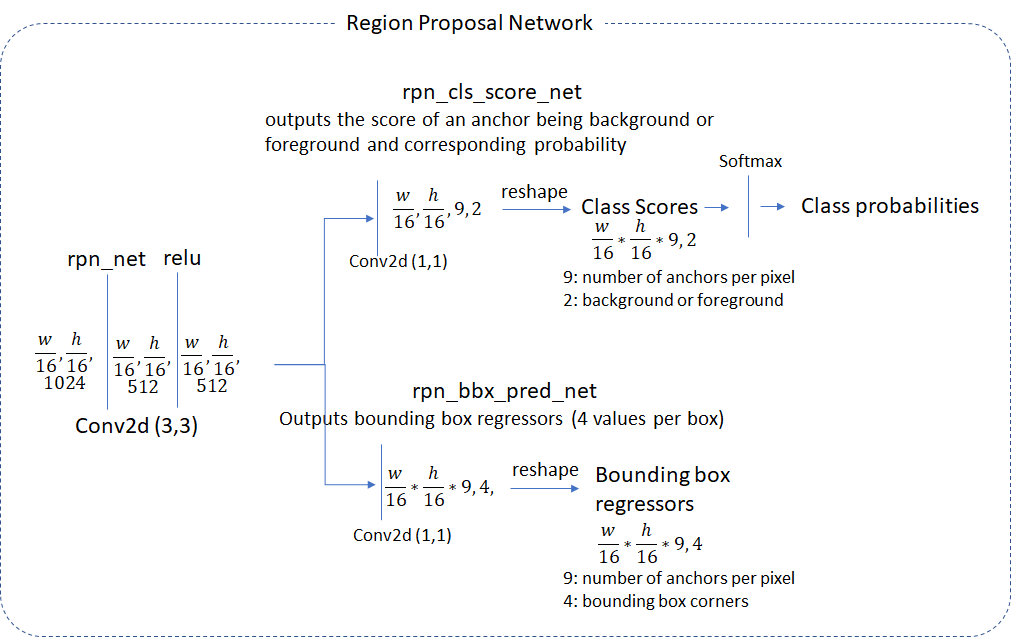
如上图所示,rpn_net通过两个1x1的卷积核,输出两个支路:rpn_cls_score_net以及rpn_bbx_pred_net,它们的高度、宽度相同,唯一不同的是深度、即通道个数。rpn_cls_score_net的通道个数为2x9=18,因为它指的是feature map上每个单元格产生的9个anchor是前景和背景的概率。rpn_bbx_pred_net的通道个数为4x9=36,因为它生成的是feature map上每个单元格产生的9个anchor的回归系数。
4. Bounding Box Regression Coefficients(回归系数)
在详细讲解Region Proposal Layer三层结构之前,我们把困扰到现在的一个问题解决,那就是:这个回归系数究竟是什么?和Anchors有什么联系?
“回归系数”即对anchors进行微调,使anchors更加接近ground truth的一组参数($t_x, t_y, t_w, t_h$)。再用大白话解释一下,我们通过anchors“机械”方式生成的RPN bboxes就算能够和ground truth比较接近,但是仍存在偏差,那么就需要一组参数对这些RPN bboxes进行回归,这也就是我们的“回归系数”bounding box regression coefficients。
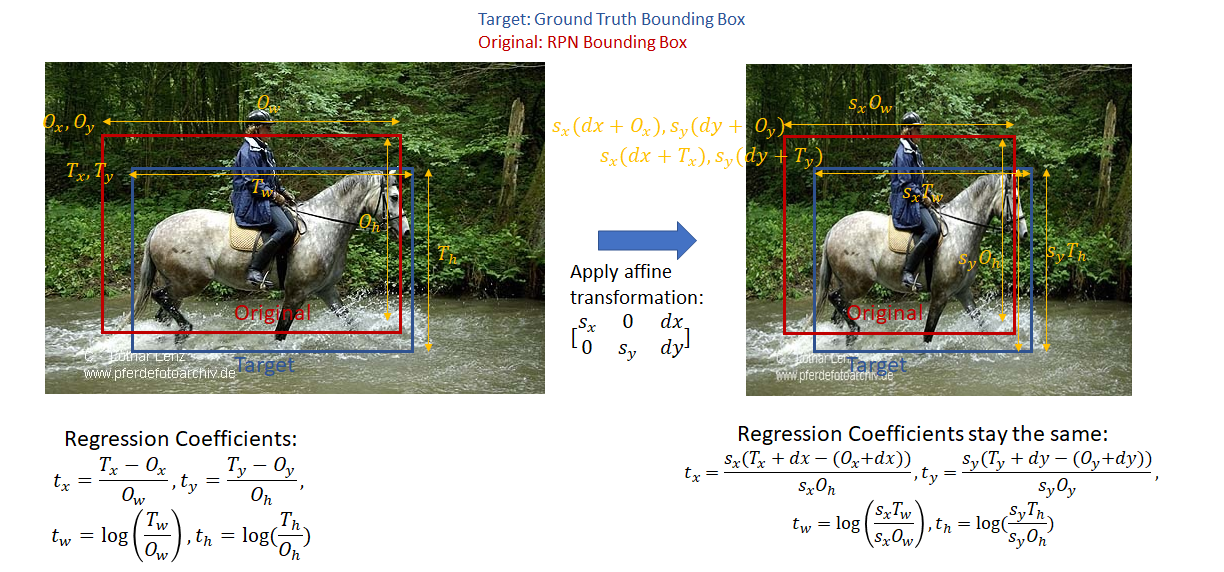
那么,这些回归系数该怎么计算呢?我们先做如下定义
$(T_x, T_y, T_w, T_h)$为目标边界框,即目标边界框的(左上角坐标x,左上角坐标y,宽,高)
$(O_x, O_y, O_w, O_h)$为原始边界框,即原始边界框的(左上角坐标x,左上角坐标y,宽,高)
那么$(t_x, t_y, t_w, t_h)$的计算过程如下:
$t_x=\frac{T_x-O_x}{O_w}$ $t_y=\frac{T_y - O_y}{O_h}$ $t_w=log(\frac{T_w}{O_w})$ $t_h=log(\frac{T_h}{O_h})$
若是不了解原始框和目标框的定义,不妨将原始框看作RPN Bbox,将目标框看作Ground Truth Bbox。这样就可以通过Anchors生成的RPN Bbox及它们各自对应的Ground Truth Bbox来计算回归系数。
在了解了什么是bounding box regression coefficients后,我们需要注意一点:当一个图片未做过剪切,只是做了仿射变换如:放大、缩小,那么该图中的bbox所对应的回归系数是不变的,因为做了等比例的转换。为什么要强调这一点,因为在后面计算分类损失的时候,目标的回归系数将按照原始纵横比计算;而分类网络输出的回归系数,是基于方块特征图经ROI池化后计算得到的。下图解释的很明白
通过对回归系数的理解后,我们可坚定的知道:rpn_bbx_pred_net输出的并不是一个框的坐标,而是每个RPN box所对应的回归系数,来调整自身的位置更好的接近Ground Truth。
5. Region Proposal Layer
Region Proposal Layer一共包含三层:Proposal Layer, Anchor Target Layer以及Proposal Target Layer。下面,我们将一层层来理解。
5.1 Proposal Layer
- Proposal Layer使用基于前景分数的non-maximum suppression来筛选anchors生成的RPN box的数量。
- 此外,还要将“回归系数”应用到RPN boxes上来生成变换后的bounding boxes。可以通过逆推公式获得bounding boxes。这里推出的bounding box是所谓的Target boudning box,是网络的预测值,并不是Groud truth box。公式里的原始边界框指的是RPN boxes。
- Proposal Layer的工作如下图所示,具体细节待补充:
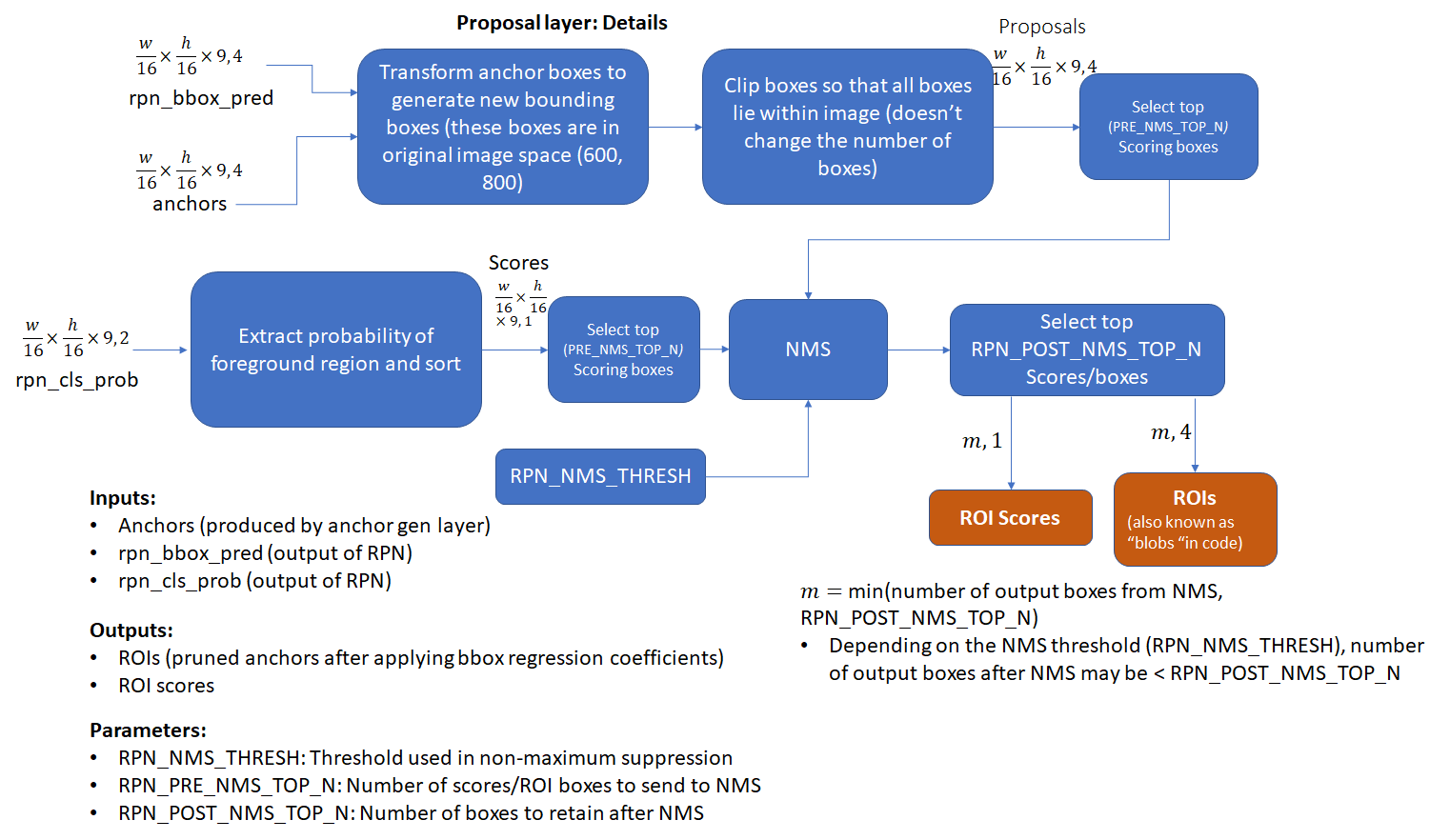
- 从图中的输出来看,此时的ROIs已经是变换坐标后的bounding box。在做非极大值抑制之前,就已经完成了坐标的转换。
5.2 Anchor Target Layer
Anchor Target Layer的目的就是选择有前途的RPN boxes,用来训练RPN网络,使得RPN网络达到以下两个功能:
- 能够区分前景和背景
- 为作为前景的RPN boxes生成好的“回归系数”
RPN的损失。为了更好的理解Anchor Target Layer,我们首先要看一下RPN的损失是怎么计算的。RPN层的主要目的是:生成更好的bounding boxes。故从一群RPN Boxes中,RPN层必须学会区分前景和背景,且要能计算“回归系数”来调整前景boxes的位置,宽度和高度,以得到一个“更好”的前景box。故RPN Loss的设计也是为了这个目的。
RPN总损失由两项损失构成:分类损失,bbox回归损失。
分类损失使用交叉熵来惩罚错误分类的bbox
$CrossEntropy(Predicted{class}, Actual{class})$
bbox回归损失使用距离函数度量真实回归系数(与作为前景的RPN box最为接近的ground truth box,通过上文提到的公式计算得到)和网络预测的回归系数。$L_{loc}$对所有前景RPN boxes的回归损失求和。作为背景的RPN box不需要进行求和,因为没有真实标签,故没意义。
$L{loc} = \sum{u\in{all \ foreground \ anchors}}l_u$
$l_u$的计算公式如下所示,计算的是RPN预测的“回归系数”和“真实回归系数”(使用离RPN bbox最近的ground truth得到)之间的差。
$lu = \sum{i\in{x, y,w,h}}smooth_{L1}(u_i(predicted) - u_i(target))$
这里的$u_i$展开来就是$(u_x, u_y, u_w, u_h)$,smooth L1函数如下所示:

这里的$\sigma$是任意选择的,为了避免for-if循环,将会使用一个掩码矩阵来计算损失
根据上述损失的定义,我们需要计算下面的量
- RPN boxes的类别标签(前景或者背景)及得分,计算类别损失
- 前景RPN boxes的目标回归系数,计算位置损失
为了得到上面的量,我们将进行以下操作
- 首先,选择位于图像范围内的RPN boxes
- 其次,通过计算所有RPN boxes和Ground Truth之间的IOU重叠来选好的前景框;通过这个IOU,两种类型的RPN bbox将会被标记为前景框
- 类型A:对于每个ground truth box,所有与他们IOU值最大的RPN Boxes
- 类型B:对于每个ground truth box,所有与他们IOU值超阈值的RPN Boxes
- 最后,图示这些盒子
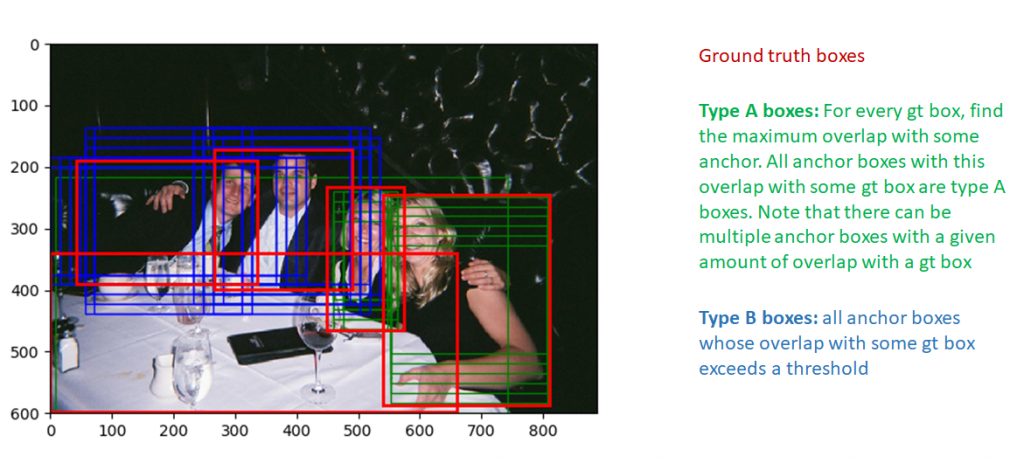
需要注意,只有与Ground Truth的IOU值超过阈值的RPN Boxes才是前景框。这样做是为了避免给RPN带来“无望的学习任务”,即由于ground truth距离太远,而导致学习到的“回归系数”过大。同理,IOU值小于负阈值的RPN Boxes被标记为背景框。
对于每一个RPN Boxes,并不是只分:前景、背景,还有一个类别:不关心(don’t care),即又不是前景又不是背景,这些盒子不包括在RPN损失的计算中。当然,前景框和背景框也有数量限制,比如说我各取128个。那么,将会从通过测试的前景框或背景框中,随即将多余出来的框标定为“don’t care”。
得到用于计算RPN Loss的候选框之后,就可以通过公式来计算出Target regression coefficients。这里用于计算位置损失的是“回归系数”,其实在理解Faster-RCNN的过程中,这个损失函数一直在困扰我。到底应该是“回归系数”,还是通过上面的公式变换得到的bbox坐标 (左上角x,左上角y,宽,高) 但不管是哪一个,通过代码可以详细了解,而且只是值的选择不同,并不影响了解Faster-RCNN的整体流程。
通过对RPN Loss的理解,我们知道了Anchor Target Layer的流程,我们最后再总结一下
- Anchor Target Layer的输入
- RPN网络的两路输出:预测的前景背景分数,回归系数
- 通过人工机械生成的RPN Boxes
- Ground Truth Boxes
- Anchor Target Layer的输出
- 用于计算RPN Loss的前景和背景框,以及与之对应的类别标签
- 目标回归系数
- Anchor Target Layer的输入
5.3 Calculating Classification Layer Loss
我们首先来了解如何计算分类层的损失以及哪些信息用来计算分类损失,以方便后续更容易了解proposal target layer, ROI Pooling layer。
和RPN Loss相似,Classification Layer Loss由两项损失组成
- Classification Loss
- Bounding Box Regression Loss
但,RPN Layer和Classificaiton Layer最大的区别就是:RPN层只需要处理两个类别:前景和背景;而分类层需要被训练处理所有的目标类别(+背景)
Classification Loss。分类的损失也是交叉熵,如下图所示。Class Scores是预测类别的得分,行数代表样本数量,列数代表总类别个数。$C_i$是每一行代表的样本真正的类别标签。0是背景类别。最后,通过Cross entropy loss,将上述参数输入,得到最后的损失值。


- Bounding Box Regression Loss。边框回归损失和RPN Loss计算方法类似,但是“回归系数”是特定于类别的。神经网络将会为每个对象类都计算回归系数,但显然,最后的目标回归系数只适用于正确的类,即与该RPN Box重叠最大的Ground Truth框的类别。在计算损失时,使用一个掩码矩阵,它为每个使用到的RPN Box标记正确的对象类。那么,不正确对象类所对应的回归系数将被忽略,这个损失可用矩阵乘法来做,而不需要for-each循环。
- 在了解了Classification Layer如何计算之后,我们需要提供以下变量以计算损失
- 分类网络的输出:预测的类别标签,回归系数
- 每个RPN Boxes的类别标签
- 目标框的回归系数
5.4 Proposal Target Layer
在了解了Classificaiton Layer的任务和需求之后,我们再先讨论一下Proposal Target Layer。
Proposal Target Layer要做的就是:从Propsoal Layer输出的一系列ROIs中选择有前途的ROIs。这些ROIs将会被用来在头网络提供的特征图中进行裁剪,然后被传递到网络的剩余部分,用于计算预测类别得分和框回归系数。
和Anchor Target Layer类似,如何选择传递到分类层的ROIs很重要,如那些与Ground Truth有明显重叠的ROIs,否则我们将要求分类层学习一个“无望的学习任务”。选择合适的ROIs的原则如下:
- 计算所有ROIs与Ground Truth的重叠值(IOU),将ROIs分为背景和前景。前景ROIs是IOU超过阈值的ROIs,背景ROIs是重叠值落在最低阈值和最高阈值之间的ROIs。这是一个“hard negative ”的典型例子,为的是给分类器提供困难的背景例子。
- 额外的逻辑保证前景和背景区域总数恒定。如发现背景区域太少,则尝试随机重复一些背景指数来填补数量的不足。
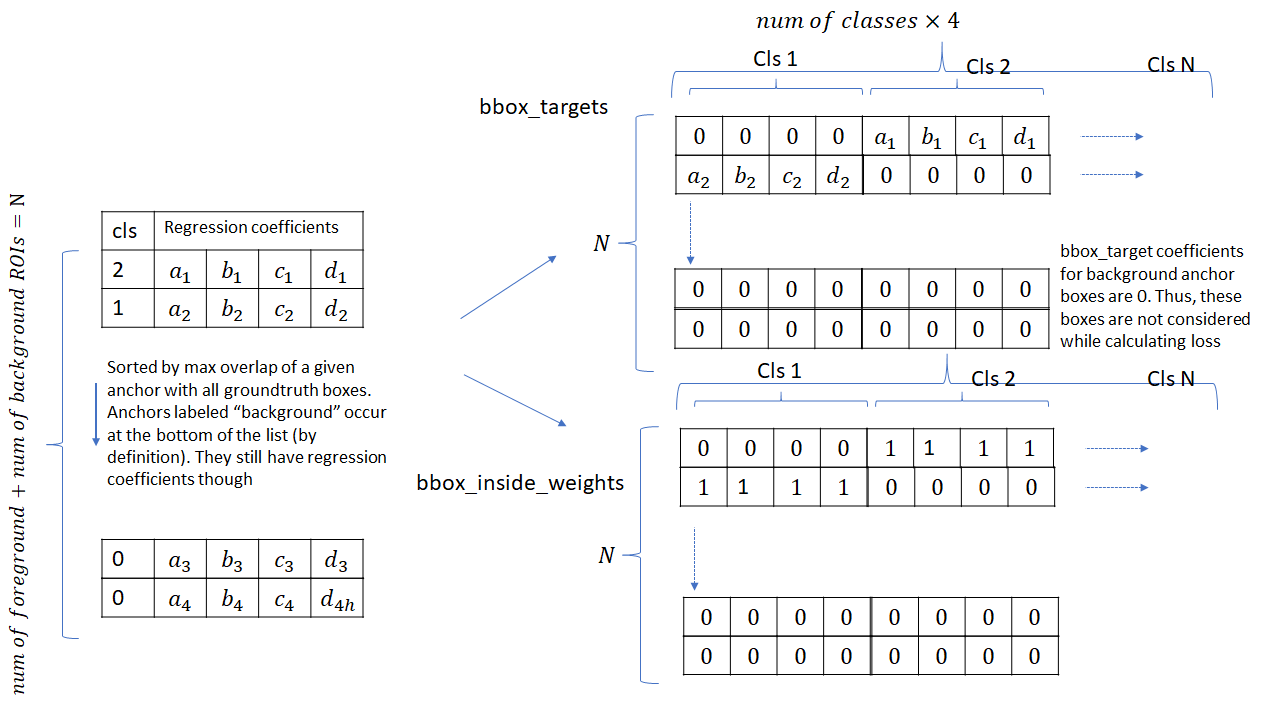
当选择到合适的ROIs后,需要计算每个ROI和离之最近的Ground Truth之间的边界框回归系数(包括背景ROIs,因为这些ROI也存在与之重叠的Ground Truth,与前面选择背景ROI的原则互相呼应)。这些回归系数将被扩展到所有类,如下图所示。
- 一共有N个ROIs的“回归系数”,根据它们与各自Ground Truth重叠大小,自高向下排列,放在列表最末尾的是标记为“背景”的ROIs的“回归系数”。目标回归系数也是N行,但是每行是(类别数 x 4),根据每个Ground Truth对应的类别标签,制作bbox_targets。真实类别处为目标回归系数(通过ROIs和Ground Truth计算得到),其余都为0。背景ROIs的的回归系数都是0,所以也不会参与损失的计算。
- bbox_inside_weights作为掩码,大小和bbox_targets一致,但是只在每个ROI正确的类别对应的位置值为1,其余值为0。对于背景ROIs,它的值也全为0。因此,当计算classification layer损失中的Bounding Box Regression Loss时,只考虑前景区域的回归系数。而计算Classification Loss的时候,前景和背景同时都要考虑。
讲到这里,很多童鞋都会有疑惑,怎么又要选择合适的框ROIs了?RPN那里不是选择了256个合适的RPN Boxes了吗,还分了前景和背景,这里为何又要重复采样,多此一举?其实,初学者都会有这样的疑惑,导致他们对Faster-RCNN的理解止步于此,因为太混乱了,就假装自己看懂了,不多想,我也曾是其中的一员。就算想通过Faster-RCNN的代码来了解详细的流程,结果又被复杂琐碎的代码劝退。如果有以上疑问,我想下面的解释会让你们茅塞顿开。要始终记住,Faster-RCNN虽然是End-2-End,但它是2-stage,不像SSD、YOLO等是1-stage。2-stage的意思就是,训练分两个阶段:首先训练RPN,达到检测目的;其次训练网络剩余部分,达到识别目的。那么,我们虽然在训练RPN的时候就完成了前景、背景框的筛选,如最后挑选出256个既包括前景又包括背景的RPN Boxes,但它们是用来训练RPN的,都是阶段1做的事情,也就说和阶段2:Classification Layer层的训练是没有关系的。当你的RPN训练的很好的时候,就能够得到比较准确的前景、背景分数及回归系数,这时候我们再开始训练Classificaiton Layer,也就是说开始阶段2了。由于阶段1和阶段2分开了,阶段2也拿不到那256个RPN Boxes用于训练RPN的样本,所以阶段2需要重新采样,经过筛选得到比较好的用于训练Classification Layer的ROIs样本框。
- 最后我们再总结一下Proposal Target Layer做的事情
- Proposal Target Layer的输入
- proposal layer提供的ROIs
- Ground Truth信息
- Proposal Target Layer的输出
- 符合重叠标准的前景和背景ROIs
- 确定好类别的ROI目标回归系数
- Proposal Target Layer的输入
6. Crop Pooling
Proposal target layer为我们提供了多个有效的,用于训练的ROIs来计算相关的类别标签和回归系数。下一步就是从头网络生成的特征图中抽取与这些ROIs相关的特征,并用剩余网络的来得到每个ROI所代表的:物体类别的概率分布,回归系数。Crop Pooling layer的工作就是从卷积特征图中进行特征抽取。
在crop pooling后的关键想法是Spatial Transformation Networks来抽取特征。CNN提取特征时,通常需要考虑输入样本的局部性、平移不变性、缩小不变性及旋转不变性,即图像的裁剪、平移、缩放、旋转。而实现这些方法就是对图像进行空间坐标变换,如仿射变化。SNT以一种统一的结构,自适应实现这些变化。SNT不需要关键点的标定,能根据分类或者其他任务自适应地将数据进行空间变换和对齐。幸运的是,Pytorch提供了两个API来实现:torch.nn.functional.affine_grid,torch.nn.functional.grid_sample。
Crop Pooling地步骤如下
- ROIs的坐标表示是相对于原图尺寸地(800 x 600),为了将这些坐标带入输出特征图的空间上,我们必须要将它们除以步长(一般为16)。
- 为了使用上述的API,我们需要仿射变换矩阵。我们需要目标特征图上的x,y维度点的数量,这个由配置参数cfg.POOLING_SIZE提供。因此,在crop pooling中,非正方形地ROIs会被用来在特征图上裁剪区域,并转变成固定大小的正方形窗口。这种转换必须要做,因为Crop Pooling地输出将会被进一步传递到卷积和全连接层,而它们需要固定维度特征。

7. Classification Layer
crop pooling层接收proposal target layer的ROIs及头网络输出的特征图作为输入,输出平方特征图。这个特征图将被传入到4层ResNet在空间维度上做平均池化,对于每个ROI,结果将会是一维特征向量,过程如下:

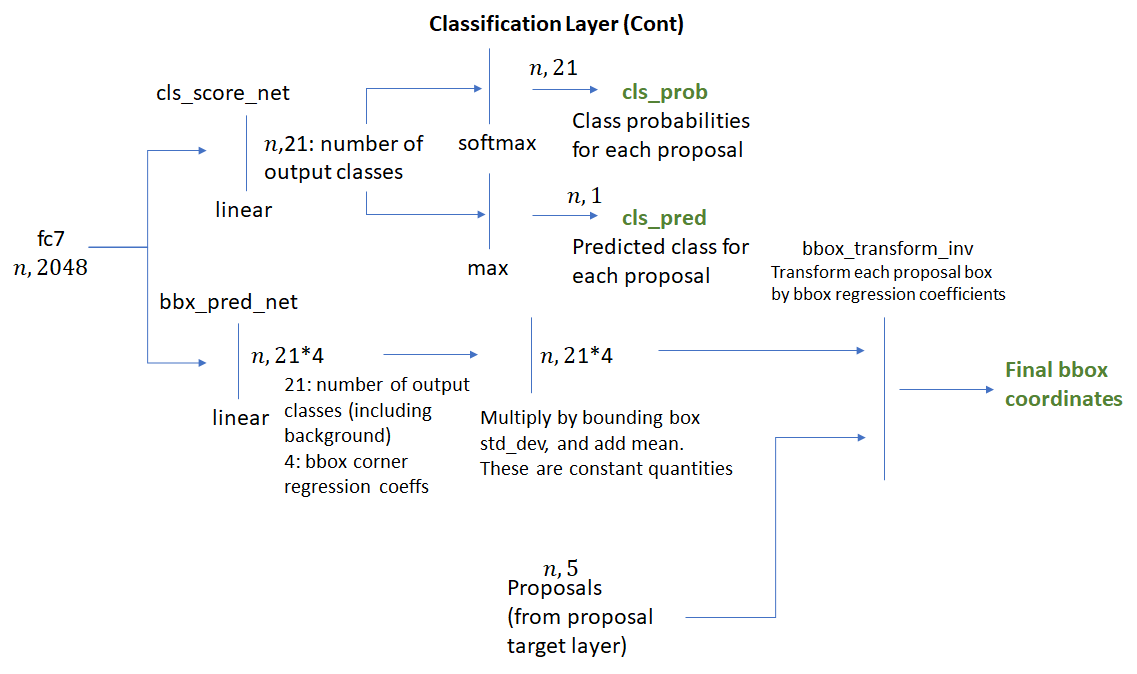
特征图被传递到两个全连接层:bbox_pred_net,cls_score_net。cls_score_net为每个bounding box产生类别分数(可通过softmax转变成概率矩阵)。bbox_pred_net生成特定类别下的边框回归系数,这些回归系数将与proposal target layer的原始边框相结合,生成最终的边界框。
最好回忆一下两组回归系数之间的差异:RPN网络产生的,classification network产生。
- 第一组RPN的回归系数用来训练RPN网络来得到更好的前景盒子(更加紧密的围绕目标边界)。此时目标回归系数,即由anchor得到的RPN Boxes与其最匹配的Ground Trouth计算得到。
- 第二组回归系数由Classification Layer生成。这些系数是特定于类别的,即每个对象类都会产生一组回归系数,最后选择正确类别的系数即可。目标回归系数将在Proposal Target Layer得到,也是通过Ground Truth匹配得到,但是需要制作成特定的形式。值得注意的是,由于仿射变化SNT使得classification network是在正方形的特征图上操作的,故可能会造成回归系数也会收到影响的误解。然而,由于回归系数对无剪切的仿射变化是不变的,因此Proposal target layer和Classification Layer之间的回归系数依然可以进行比较,作为有效的学习信号。
值得注意的是,训练Classification Layer时,错误的梯度也会反向传播到RPN网络。这是因为在Crop Pooling时,使用的ROIs本身就是网络的输出,是RPN网络生成回归系数应用到RPN Box的结果。故在反向传播期间,误差梯度将通过crop pooling传播到RPN层。计算和应用这些梯度很难实现,但Pytorch提供了很好的crop pooling API,方便了细节的处理。
8. 实现细节:推理
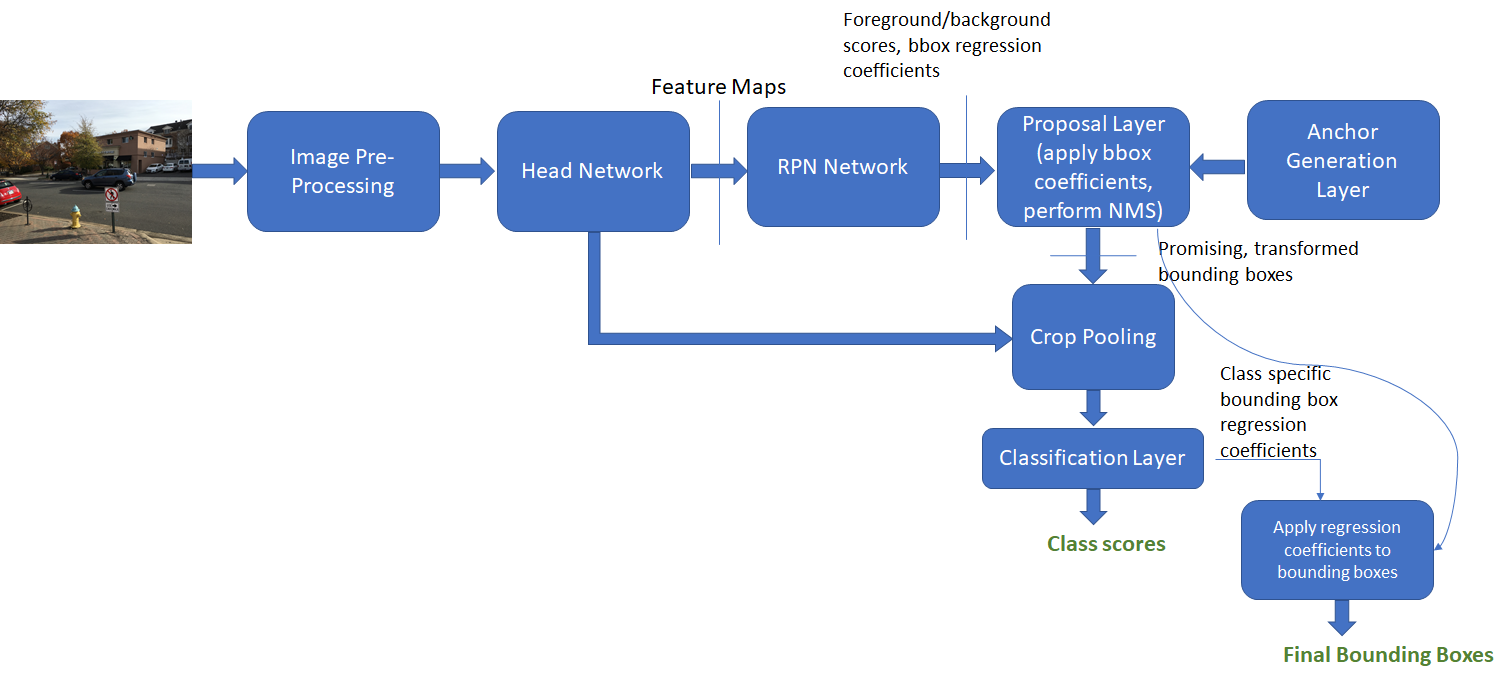
- Anchor target和Proposal Target Layer不参与此过程。RPN网络将RPN Boxes分类成:前景、背景,并生成良好的框回归系数。Proposal Layer仅仅将回归系数应用到RPN Boxes并进行非极大值抑制来消除大量重叠的框,最后的剩余的框将被送到Classification Layer生成类得分及基于类别的边框回归系数。
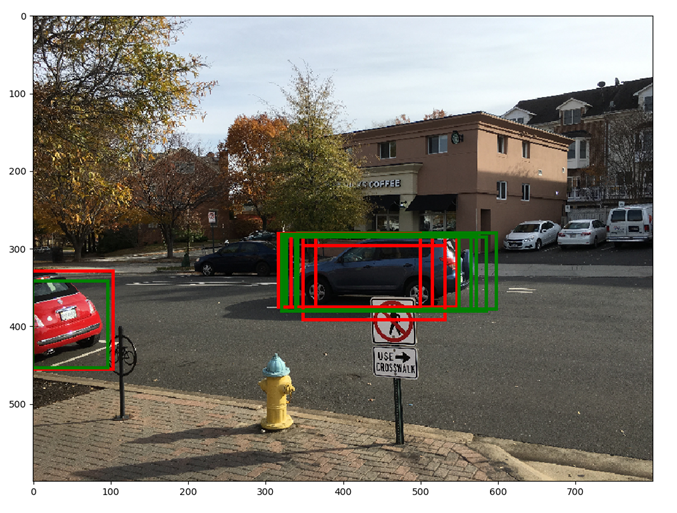
红框显示的是排名前6的RPN Boxes。绿框表示应用RPN Boxes的回归系数后的框,显然绿框更加适合目标。在应用回归系数后,矩形依然是矩形,即存在显著的重叠,这种冗余需要通过非极大值抑制来解决。
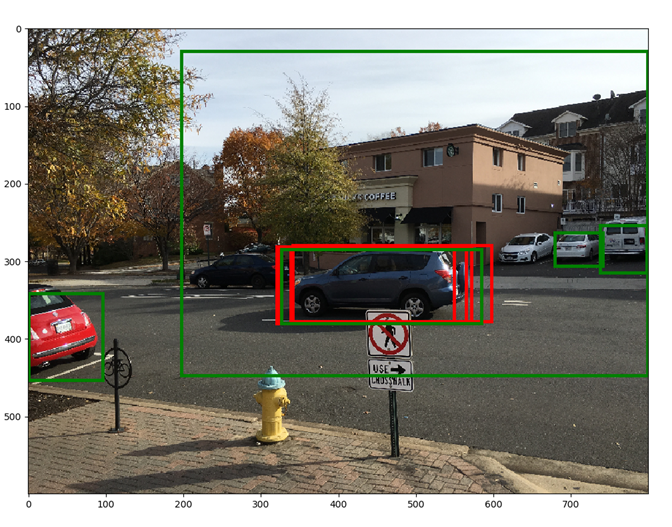
红色框表示非极大值抑制之前的5个框,绿色框表示非极大值抑制后的5个框。通过抑制重叠框,其他框(得分较低的框)就有机会向上移动了。

通过最后的分类分数数组(dim:n, 21),我们选择分数最大的作为类别。并选择该类别所对应的框回归因子来调整框,它比其他因子更加适合调整这个特定的类别。最后的检测结果如下图所示: